
GAN,VAE和流模型的原理(以流模型为主)
GAN,VAE和流模型的原理(以流模型为主)
2025/02/26 以便自己查看
生成式神经网络
生成式神经网络是一种以生成与被提供的数据集相似的新数据为目的的人工神经网络。它试图构建一种模型分布\(p_{model}\),使其尽可能接近原始数据分布\(p_{data}\)。由于不依赖其他标签数据,生成式模型往往是无监督学习。 特别的,生成式模型也可以预测在\(y\)条件下\(x\)的分布\(P(x|y)\),比如要求一个用于生成水果图像的模型生成一个苹果:\(P(\text{水果}|\text{苹果})\)。
对于数据的集合\(\mathbf{X}\),生成式神经网络理想的损失函数是模型分布和数据分布之间的似然函数:
\[ \begin{align} \mathcal{L}(model(\theta) \mid \mathbf{X})= \prod_{x \in \mathbf{X}} p_{model(\theta)}(x)\end{align} \]
似然函数是模型可调节参数\(\theta\)的函数,用于衡量模型分布对数据分布的拟合程度,所以最大化似然函数是模型训练的目的。 在实际训练中,我们不希望计算大量0到1之间的数值的乘积,并且我们希望最小化损失函数,因此一般使用负对数似然函数作为损失函数。理想的模型参数\(\hat \theta\)即为负对数似然函数取最小值时的模型参数:
\[ \begin{align} &loss=-\sum_{x \in \mathbf{X}} \log p_{model(\theta)}(x)\\ &\hat \theta = argmin(-\sum_{x \in \mathbf{X}} \log p_{model(\theta)}(x))\end{align} \]
然而,对于高维问题,直接计算概率\(p_{model(\theta)}(x)\)是不可行的。对此,有三种主流的解决方法:隐性建模,近似显性建模和易解显性建模。
- 隐性建模不关注于分布的估计,这些模型专注于数据的生成,并使用其他方法保证生成的数据与真实数据分布接近。
- 近似显性建模尝试使用近似方式估测模型分布和数据分布间的差异。
- 易解显性建模直接定义了方便求解的似然分布,并且直接应用似然函数优化模型。
GAN 生成对抗网络
对抗生成网络(GAN)包含两个子网络,分别称为生成器(G)和判别器(D)。前者从某一简单分布\(p_Z(z)\)出发,构建模型分布\(p_{G}(x)\)。后者分辨数据来源自生成还是属于真实数据,并将由生成器生成的数据标记为0,真实数据标记为1。
具体来说,GAN并没有使用最大似然函数法进行模型训练,而是重新定义了一个最小最大问题,即最小化生成器的欺骗判别器的能力,并最大化判别器的辨识由生成器生成的数据的能力。
\[ \begin{align} & V(G,D) = \mathbb{E}_{x \sim p_{data }(x)}[\log D(x)]+\mathbb{E}_{z \sim p_{z}(z)}[\log (1-D(G(z)))] \\ & G^*, D^* = \underset{G}{\operatorname{argmax}} \ \underset{D}{\operatorname{argmax}} V(G,D)\end{align} \]
在细节方面,为了训练模型,需评价模型分布\(p_{G}(x)\)和数据分布\(p_{data}(x)\)的相似性。在GAN中,辨别器扮演这一角色。我们将重点关注这种方法的理论依据。假设生成器参数固定,展开V(G,D)得:
\[ \begin{align} V(G,D)&=\int_{x} \left[p_{data }(x) \log (D(x))+p_{G}(x) \log (1-D(x))\right] d x\end{align} \]
设D在这种情况下的的最佳参数取值\(D^*\)为:
\[ \begin{align} D^* &= \underset{D}{\operatorname{argmax}} \int_{x} \left[p_{data }(x) \log (D(x))+p_{G}(x) \log (1-D(x))\right] d x\end{align} \]
其中,\(p_{data }(x) \log (D(x))+p_{G}(x) \log (1-D(x))\)在\([0,1]\)之间有最大值。求导以求出最大时对应的\(D(x)\)的表达式,可得在生成器网络参数固定时,对于每一个\(x\),理想的判别器\(D^*\)为:
\[ \begin{align} D^*(x) = \frac{p_{data}(x)}{p_{data}(x)+p_{G}(x)}\end{align} \]
将这一表示带回公式\((4)\):
\[ \begin{align} V(G,D^*)&=\mathbb{E}_{x \sim p_{data }(x)}[\log \frac{p_{data}(x)}{p_{data}(x)+p_{G}(x)}]\nonumber\\ &+\mathbb{E}_{z \sim p_{G}(x)}[\log \frac{p_{G}(x)}{p_{data}(x)+p_{G}(x)}] \end{align} \]
为了进一步理解公式,引入KL散度和JS散度。它们都是衡量两个概率分布之间的相似性的指标。
\[ \begin{align} &D_{K L}(p || q)=\mathbb{E}[\log \frac {p\left(x_i\right)}{q\left(x_i\right)}]\\ &D_{J S}(p || q)=\frac{1}{2} D_{K L}(p || \frac{p+q}{2})+\frac{1}{2} D_{K L}(q || \frac{p+q}{2})\end{align} \]
使用两种散度表示公式\((9)\),可得:
\[ \begin{align} V(G,D^*)&=-\log(4)+2\cdot D_{JS}(p_{data}||p_{G})\end{align} \]
由此可知,在理想情况下,GAN期望训练判别器网络,使得其近似于数据分布和模型分布的JS散度,从而将其作为衡量两个分布相似性的指标。然后使用由判别器网络近似的JS散度作为损失函数,并将其最小化获得最优的生成器模型。
实际情况下,在GAN的训练中,生成器和判别器的训练是交替进行的,因此为了达到上述效果,只能期望在一次将判别器训练至最优。但这是十分难以实现的。实际情况下损失函数是通过神经网络方法对JS散度的隐性近似。
VAE 变分自动编码器
变分自动编码器(VAE)是贝叶斯概率在深度学习领域中最广为人知的应用之一。VAE包含编码器(E)和解码器(D)两个网络。在生成时,从某先验分布\(p_Z(z)\)中采样潜在空间向量\(z\),并使用解码器解码得到\(x\)。 由于似然度难以直接计算,VAE使用变分方法和KL散度确定了似然度的下界,然后对下界进行进一步的优化
具体来说,解码器代表给定潜在空间向量z时,变量x的条件分布\(p_{model_D}(x|z)\),根据全概率公式和贝叶斯定理,可以将模型分布\(p_{D}(x)\)表示为潜在空间向量的先验分布和条件分布的乘积的积分:
\[ \begin{align} p_{D}(x)=\int p_{D}(x|z)p_{Z}(z)dz\end{align} \]
在这个公式中,\(p_{D}(x)\)与前文的\(p_{model(\theta)}(x)\)等价,代表VAE模型中的模型分布。此时,负对数似然可以表示为:
\[ \begin{align} &loss=-\sum_{x \in \mathbf{X}} \log p_{D}(x) = -\sum_{x \in \mathbf{X}} \log \int p_{D}(x|z)p_{Z}(z)dz \end{align} \]
然而,这个高维积分有着很高的计算复杂度,是难以计算的。一个可行的简化思路为缩小连续随机变量z的取值范围,将积分问题转化为求和问题。在这个过程中,为了不影响生成的精度,尽可能选取最能生成可靠数据的潜在空间向量是至关重要的。为此,VAE不再使用z的先验分布,而是使用与真实数据相联系的后验概率分布。
\[ \begin{align} p_{D}(z|x) = \frac{p_{D}(x|z)\cdot p_{Z}(z)} {p_{D}(x)} \end{align} \]
由于\(p_{D}(x|z)\)和\(p_{D}(x)\)难以表述,后验概率的直接计算同样是不可能的。为此,需要引入编码器,构成另一个分布\(q_E(z|x)\)去近似后验概率分布,并同时引入KL散度作为两个分布相似程度的评价标准。
$$ \[\begin{align} D_{KL}(q_E(z|x)||p_{D}(x|z)) &= \mathbb{E}_{z\sim q_E(z|x)}\left[\log\left(\frac{q_E(z|x)}{p_{D}(x|z)}\right)\right] = \mathbb{E}_{z\sim q_E(z|x)}\left[\log\frac{q_E(z|x)\cdot p_{D}(x)}{p_{Z}(z) \cdot p_{D}(x|z)}\right]\nonumber\\ & = D_{KL}(q_E(z|x)||p_{Z}(z))- \mathbb{E}_{z\sim q_E(z|x)}\left[p_{D}(x|z)\right]+ \log p_{D}(x) \end{align}\] $$
其中,\(\log p_{D}(x)\)是我们需要计算最小负对数似然的部分,整理公式得:
\[ \begin{align} \log p_{D}(x) = D_{KL}(q_E(z|x)||p_{D}(x|z)) + \mathbb{E}_{z\sim q_E(z|x)}\left[p_{D}(x|z)\right]-D_{KL}(q_E(z|x)||p_{Z}(z)) \end{align} \]
尽管\(D_{KL}(q_E(z|x)||p_{D}(x|z))\)依然无法运算,但其恒为正数,仅在\(q_E(z|x)\)和\(p_{D}(x|z)\)完全相同时取0,因此\(\log p_{D}(x)\)的下界可以确认。这个下界被称为变分下界,是VAE的核心思想。
\[ \begin{align} \log p_{D}(x) \ge \mathbb{E}_{z\sim q_E(z|x)}\left[p_{D}(x|z)\right]-D_{KL}(q_E(z|x)||p_{Z}(z)) \end{align} \]
其中,第一项衡量输入向量x和将其编码为z,再解码得到的新数据\(\hat x\)的差异,称为重构误差。第二项衡量编码器和先验分布之间的差异。通过变分下界,VAE成功的取得了似然函数的近似值,使得模型训练成为可能。
流模型
流模型的可逆性和雅可比行列式可计算性
易解显性建模的关键在于似然分布的计算。流模型通过本身具备的可逆性和雅可比矩阵行列式可计算性,将难以计算似然的分布转化为如正态分布这般易于计算的分布
具体来说,流模型定义了一组可逆函数\(x=g(z) \Leftrightarrow z=f(x)\)可逆将输入向量\(x\)从样本空间映射到潜在空间,并假定潜在空间向量\(p_{model}(z)\)为多元标准正态分布。根据双射的性质,\(x\)和\(z\)必须是等维度的。根据概率密度的换元公式,有:
\[ \begin{align} &p_{model}(x) = p_{model}(z)\left | det\left(\frac{\partial z}{\partial x}\right)\right |\end{align} \]
其中,\(det\left(\frac{\partial z}{\partial x}\right)\)是雅克比矩阵行列式,用于保证在换元过程中概率密度函数是归一的。由此,对数似然可以表示为:
\[ \begin{align} &\sum_{x \in \mathbf{X}} \log p_{model}(x) = \sum_{x \in \mathbf{X}} \log p_{model}(z) + \sum_{x \in \mathbf{X}} log\left | det\left(\frac{\partial z}{\partial x}\right)\right |\end{align} \]
对于第一项,一个k维的多元标准正态分布的概率密度函数为:
\[ \begin{align} p_{model}(z)=\frac{1}{(2 \pi)^{\frac{k}{2}}} \exp \left(-\frac{1}{2} z^T z\right)\end{align} \]
假设输入样本数量为N,公式\((20)\)的第一项即可表示为:
\[ \begin{align} \sum_{x \in \mathbf{X}} \log p_{model}(z) = \sum_{x \in \mathbf{X}}\left(-\frac{k}{2} \log (2 \pi)-\frac{1}{2} z_i^T z_i\right) = -\frac{N k}{2} \log (2 \pi)-\frac{1}{2} \sum_{i=1}^n z_i^T z_i\end{align} \]
对于固定的数据表示方式和数据集,公式\((22)\)的第一项为常数,不会影响梯度下降过程。第二项即为潜在向量的平方和,其计算复杂度仅为\(O(kN)\),十分便于计算。公式\((20)\)的第二项是雅可比矩阵的行列式的对数和,单个\(k\cdot k\)的矩阵的行列式运算复杂度已经达到了\(O(k^3)\)。 这意味着常规情况下我们不可能把一个需要计算雅可比矩阵行列式的函数作为损失函数。因此,流模型的主要设计目标是通过网络结构的设计,保证雅可比矩阵的可计算性。另一个设计重点是函数\(z = f(x)\)的可逆性。如果只能实现从样本空间到潜在空间的映射,即使计算似然度是成功的,模型也并不具备生成能力,这将背离生成式神经网络的初衷。

在原理上,流模型通过构建可逆且雅可比行列式可计算的子层来保证网络整体的两个相应性质。雅可比行列式可计算性一般借助对角矩阵的行列式即为其对角线乘积的特点和行列式本身的乘法性质。假设\(f_i\)是组成流模型的子层,\(g_i\)是相应的逆函数,整体网络可以被表示为\(f = f_n \circ \ldots \circ f_2 \circ f_1, \ g = g_n \circ \ldots \circ g_2 \circ g_1\),如图所示。其中,蓝色框代表节点,\(\mathbf{X}\)为样本空间中的数据,\(\mathbf{Z}\)为潜在空间中的数据。数据就像流体一样在模型中流动。此时行列式可以用以下公式表示:
\[ \begin{align} det\left(\frac{\partial z}{\partial x}\right) = det\left(\frac{\partial f(x)}{\partial x}\right) = det\left(\frac{\partial ( f_n \circ \ldots \circ f_2 \circ f_1(x))}{\partial x}\right)\end{align} \]
根据链式法则,可以将公式(23)展开为:
\[ \begin{align} det\left(\frac{\partial z}{\partial x}\right) =det\left(\frac{\partial \left( f_n \circ \ldots \circ f_2 \circ f_1(x)\right)}{\partial \left(f_{n-1} \circ \ldots \circ f_2 \circ f_1(x)\right)}\cdot\ldots\cdot\frac{\partial \left(f_2 \circ f_1(x)\right)}{\partial \left(f_1(x)\right)}\cdot\frac{\partial f_1(x)}{\partial x}\right)\end{align} \]
根据行列式乘法定义,进一步展开公式(24):
\[ \begin{align} det\left(\frac{\partial z}{\partial x}\right) =det\left(\frac{\partial \left( f_n \circ \ldots \circ f_2 \circ f_1(x)\right)}{\partial \left(f_{n-1} \circ \ldots \circ f_2 \circ f_1(x)\right)}\right)\cdot\ldots\cdot det\left(\frac{\partial \left(f_2 \circ f_1(x)\right)}{\partial \left(f_1(x)\right)}\right)\cdot det\left(\frac{\partial f_1(x)}{\partial x}\right)\end{align} \]
如果每个子层的雅可比矩阵都为对角阵,则(25)是易于计算的。因此,子层的雅可比矩阵行列式可计算性和可逆性,是流模型具备相应两个性质和易解显性建模可行的充分条件。最终,通过对模型的设计,流模型在不做任何近似的情况下,可以使用一种具备可接受时间复杂度的方式,表述原本难以计算的似然函数。
流模型的基本实现原理
流模型的实现依赖于具备可逆性和雅可比行列式可计算性的子层的实现。然而,在实践中,寻找一种同时具备可逆性和雅可比矩阵可计算性的神经网络子层同样是十分具有挑战性的。在流模型中,经典的解决方法是使用耦合层(coupling layer)。
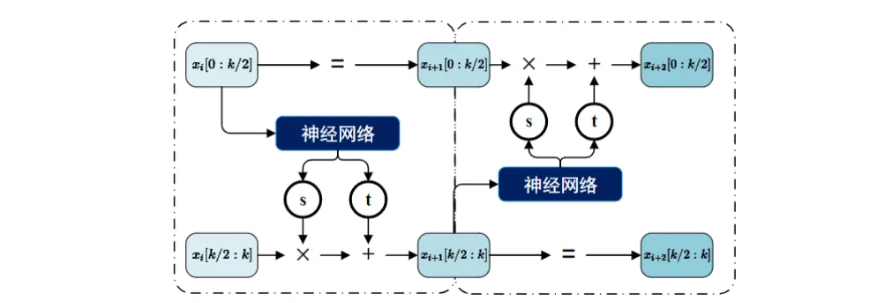
图中是一种经典的耦合层的正向变换方式,图中包含两个耦合层。其中\(x_i\)代表数据,\(s\)和\(t\)分别为耦合层神经网络计算给出的缩放因子和平移因子。在使用耦合层处理数据时,首先会将数据分为两个部分,在经过一次耦合层时,第一部分数据\(x_{i}[1:k/2]\)进入耦合层神经网络,并通过计算给出缩放因子\(s\)和平移因子\(t\)。然而,与一般的神经网络不同的是,这并不意味着第一部分数据发生了任何的改变。应用神经网络的目的是为了得到指引第二部分数据\(x_{i}[k/2+1:k]\)变换的因子:
\[ \begin{align} \left\{ \begin{aligned} &x_{i+1}[1:k/2] = x_{i}[1:k/2]\\ &x_{i+1}[k/2+1:k] = x_{i}[k/2+1:k] \odot \exp(s(x_{i}[1:k/2])) + t(x_{i}[1:k/2]) \end{aligned} \right.\end{align} \]
其中,\(\odot\)为元素级别的乘法。为了避免指数项\(\exp(s(x_{i}[1:k/2]))\)过大而破坏模型稳定性,将\(s\)限定在\([-1,1]\)之间是必要的。根据公式(26),发现\(x_{i+1}[1:k/2]\)与\(x_{i+1}[k/2+1:k]\)完全无关。这意味着雅可比矩阵是下三角矩阵(或上三角矩阵,如果保持不变的是后半部分)。计算这一层内的雅可比矩阵行列式:
\[ \begin{align} det\left(\frac{\partial x_{i+1}}{\partial x_{i}}\right) = \left|\begin{array}{ccc} \frac{\partial x_{i+1}[1]}{\partial x_{i}[1]} & \cdots & \frac{\partial x_{i+1}[1]}{\partial x_{i}[k]} \\ \ddots & \vdots & \\ \frac{\partial x_{i+1}[k]}{\partial x_{i}[1]} & \cdots & \frac{\partial x_{i+1}[k]}{\partial x_{i+1}[k]} \end{array}\right| = \left|\begin{array}{cc} \mathbf{I} & 0 \\ \frac{\partial x_{i+1}[k/2+1: k]}{\partial x_{i}[1: k/2]} & \operatorname{diag}\left(\exp \left[s\left(x_{i}[1: k/2]\right)\right]\right) \end{array}\right|\end{align} \]
三角矩阵的行列式即为对角线乘积:
\[ \begin{align} det\left(\frac{\partial x_{i+1}}{\partial x_{i}}\right) = \exp(\left[\sum s\left(x_{i}[1: k/2]\right)\right])\end{align} \]
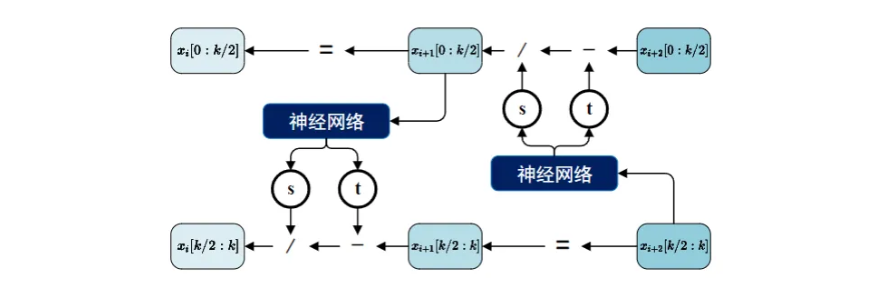
因此,耦合层的雅可比矩阵行列式是易于计算的,其时间复杂度为\(O(k)\)。然后关注另一个必要的性质,可逆性。首先,耦合层的输入和输出是等维度的,这保证了可逆性的必要条件。然后,耦合层的每一次变换都保证了有一部分数据没有发生改变,且整体变换仅依赖于这部分不变的数据。这使得逆函数非常容易设计,如图所示。
\[ \begin{align} \left\{ \begin{aligned} &x_{i}[1:k/2] = x_{i+1}[1:k/2]\\ &x_{i}[k/2+1:k] = x_{i+1}[k/2+1:k] \div \exp(s(x_{i+1}[1:k/2])) - t(x_{i+1}[1:k/2]) \end{aligned} \right.\end{align} \]
在单层可逆且雅可比矩阵行列式可计算的基础上,根据公式(25)的原理堆叠多个耦合层,即可实现流模型。



