
RM2 CDMA编码和干扰
RM2 CDMA编码和干扰
CDMA 编码
为了构建上述正交编码,一种简单的方法是使用Wash-Hadamard
编码。这种方法递归构建一个矩阵,编码即为矩阵的每一行:
\[ \begin{gathered} H_1=[1] \ , \ H_{2^n}=\left[\begin{array}{cc} H_{2^{n-1}} & H_{2^{n-1}} \\ H_{2^{n-1}} & -H_{2^{n-1}} \end{array}\right] \end{gathered} \]
如对于\(L = 4\)时,矩阵可以如下构建:
\[ \begin{aligned} &\begin{aligned} & H_1=[1] \\ & H_2=\left[\begin{array}{cc} H_1 & H_1 \\ H_1 & -H_1 \end{array}\right]=\left[\begin{array}{cc} 1 & 1 \\ 1 & -1 \end{array}\right] \end{aligned}\\ &H_4=\left[\begin{array}{cc} H_2 & H_2 \\ H_2 & -H_2 \end{array}\right]=\left[\begin{array}{cc:cc} 1 & 1 & 1 & 1 \\ 1 & -1 & 1 & -1 \\ \hdashline 1 & 1 & -1 & -1 \\ 1 & -1 & -1 & 1 \end{array}\right] \end{aligned} \]
\(H_4\)中的四行即为四个正交编码。
接下来,我们来讨论\(L\)的取值对带宽的影响。回忆方波的傅里叶变换:
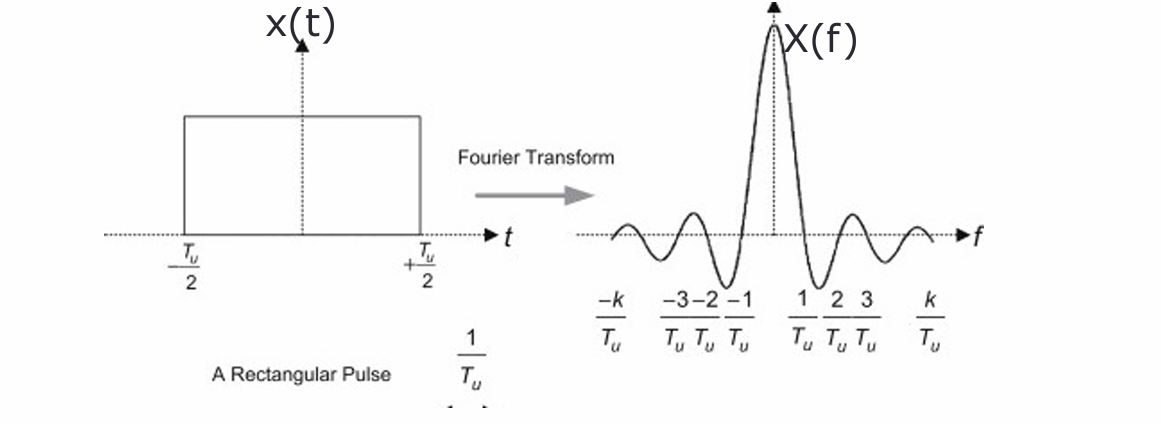
带宽与方波的周期的倒数\(1/T_u\)成正比。我们使用的编码信号的周期通常为原始信号的\(1/L\),即编码信号的带宽通常大于原始信号。它们在时域上相乘意味着在频域上的卷积,即:
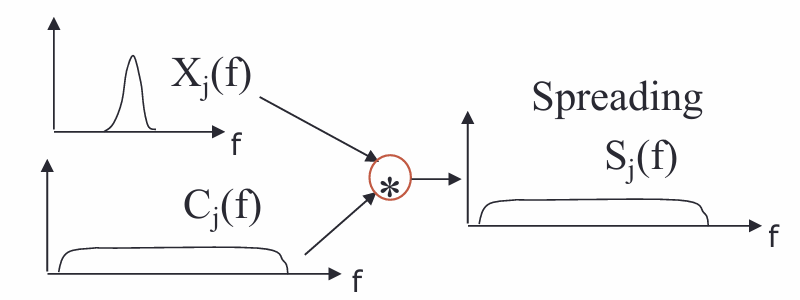
因此,在编码之后,带宽会增大,信号被扩频。这也是这种方法被称为直接信号扩频spread spectrum by direct sequence的原因。
由于信号的总带宽有限,我们不能无限制的增大编码数量。或者从另一个角度来看,设由于带宽限制导致的最小周期为\(T_c\),原始信号周期即为:
\[ T_s = LT_c \]
信号速率\(R_x=\frac{1}{T_s}=\frac{1}{L T_c}\)随着\(L\)的则更加而降低。因此,虽然可以通过扩大\(L\)来扩展系统容量,但会牺牲单个信号的效率。
OVSF 正交可变扩展因子码树
在先前的处理中,我们假设了所有的用户使用了相同的速率\(R_x\),现在我们考虑不同的用户可能使用不同的速率的情况。在带宽固定的情况下,不同的速率意味着不同的用户有不同的\(L\)。OVSF是一种在3G网络中被应用的解决方案。

OVSF建立了不同\(L\)的编码之间的正交性关系。在不同枝干上码之间保持正交,在同一枝干上的码不具备正交性。如\(C_{4,1}\)与\(C_{4,2}\)或者\(C_{8,7}\)等编码属于不同的分叉,它们之间具备正交性;而\(C_{4,1}\)与\(C_{8,0}\)属于同一分支,它们之间不具备正交性,因此在使用其中一个之后,不能再使用另一个。
再这种情况下,假设第\(i\)组使用速率为\(R_i\)的信号,对应\(L_i\)的编码。需满足:
\[ \sum_{i=1}^N \frac{K_i}{L_i} \leq 1 \]
其中\(K_i\)为第\(i\)组的可容纳用户数量。
CDMA的干扰和解决方案
干扰问题
另一个影响用户容量的因素时干扰interference
。干扰将破坏编码的正交性。一种干扰的来源时多径信道。接下来,我们来看一些双径信道的例子。
假设用户初始发射的信号为:
\[ \underbrace{x_1^i c_0^i, x_1^i c_1^i, \ldots, x_1^i c_{L-1}^i}_{x_1^i} ,\underbrace{x_2^i c_0^i, x_2^i c_1^i, \ldots, x_2^i c_{L-1}^i}_{x_2^i}, \ldots \]
在接受时,除了直接路径信号\(\underbrace{x_1^i c_0^i, x_1^i c_1^i, \ldots, x_1^i c_{L-1}^i}_{x_1^i} ,\underbrace{x_2^i c_0^i, x_2^i c_1^i, \ldots, x_2^i c_{L-1}^i}_{x_2^i}, \ldots\)之外,还接受到一个延迟了一个\(T_c\)的信号\(\underbrace{0,x_1^i c_0^i, x_1^i c_1^i, \ldots, x_1^i c_{L-1}^i}_{x_1^i} ,\underbrace{x_2^i c_0^i, x_2^i c_1^i, \ldots, x_2^i c_{L-1}^i}_{x_2^i}, \ldots\)
两个信号叠加后,我们以\(x_2^i\)为例,将转变为:
\[ \left[\begin{array}{llll}x_2^i c_0^i+x_1^i c_{L-1}^i & x_2^i c_1^i+x_2^i c_0^i & \cdots & x_2^i c_{L-1}^i+x_2^i c_{L-2}^i\end{array}\right] \]
尝试解码:
\[ \frac{1}{L}\left[x_2^i c_0^i+x_1^i c_{L-1}^i \quad x_2^i c_1^i+x_2^i c_0^i \quad \cdots \quad x_2^i c_{L-1}^i+x_2^i c_{L-2}^i\right]\left[\begin{array}{c} c_0^i \\ c_1^i \\ \vdots \\ c_{L-1}^i \end{array}\right] =\frac{1}{L} x_2^i\left(\sum_{l=0}^{L-1}\left(c_l^i\right)^2\right)+\frac{1}{L} x_2^i\left(\sum_{l=1}^{L-1} c_l^i c_{l-1}^i\right)+\frac{1}{L} x_1^i c_0^i c_{L-1}^i \]
第一项是应该得到的目标,解码的性能取决于编码的自相关项\(\frac{1}{L}\left(\sum_{l=1}^{L-1} c_l^i c_{l-1}^i\right)\)。
当我们把相同的情况扩展到双用户,假设两个用户发射的信号分别为:
- \(\underbrace{x_1^i c_0^i, x_1^i c_1^i, \ldots, x_1^i c_{L-1}^i}_{x_1^i}, \underbrace{x_2^i c_0^i, x_2^i c_1^i, \ldots, x_2^i c_{L-1}^i}_{x_2^i}, \ldots\)
- \(\underbrace{x_1^j c_0^j, x_1^j c_1^j, \ldots, x_1^j c_{L-1}^j}_{x_1^j}, \underbrace{x_2^j c_0^j, x_2^j c_1^j, \ldots, x_2^j c_{L-1}^j}_{x_2^j}, \ldots\)
那么以\(x_2^i\)为例,接收到的信号为:
\[ \left[\begin{array}{c}x_2^i c_0^i+x_1^i c_{L-1}^i+x_2^j c_0^j+x_1^j c_{L-1}^j \\x_2^i c_1^i+x_2^i c_0^i+x_2^j c_1^j+x_2^j c_0^j \\\vdots \\x_2^i c_{L-1}^i+x_2^i c_{L-2}^i+x_2^j c_{L-1}^j+x_2^j c_{L-2}^j\end{array}\right]^T \]
尝试解码,有:
\[ \frac{1}{L}\left[\begin{array}{c}x_2^i c_0^i+x_1^i c_{L-1}^i+x_2^j c_0^j+x_1^j c_{L-1}^j \\x_2^i c_1^i+x_2^i c_0^i+x_2^j c_1^j+x_2^j c_0^j \\\vdots \\x_2^i c_{L-1}^i+x_2^i c_{L-2}^i+x_2^j c_{L-1}^j+x_2^j c_{L-2}^j\end{array}\right]^T\left[\begin{array}{c}c_0^i \\c_1^i \\\vdots \\c_{L-1}^i\end{array}\right]=\frac{1}{L} x_2^i\left(\sum_{l=0}^{L-1}\left(c_l^i\right)^2\right)+\frac{1}{L} x_2^i\left(\sum_{l=1}^{L-1} c_l^i c_{l-1}^i\right)+\frac{1}{L} x_1^i c_0^i c_{L-1}^i+\frac{1}{L} x_2^j(\underbrace{\sum_{l=0}^{L-1} c_l^i c_l^j}_{=0})+\frac{1}{L} x_2^j(\underbrace{\sum_{l=1}^{L-1} c_l^i c_{l-1}^j}_{\neq 0})+\frac{1}{L} x_1^j c_0^i c_{L-1}^j \]
除了在单用户问题中已经呈现出来的自相关项影响,两个编码的互相关也会对信号产生影响。与自相关项不同,互相关项会带来来自其他信号的干扰。
既然已经了解到干扰主要由互相关项导致,我们将视线转向编码的互相关。比如如下两个编码:
\[ \begin{aligned}& c^i,: 1\ \ 1-1-1 \\& c^j: 1-1-1\ \ 1\end{aligned} \]
它们的互相关为3,两信号之间会产生干扰。为了解决这个问题,有两种方案:随机序列random sequence
或伪随机序列pseudo noise sequence
。前者主张随机生成每个用户的编码,使他们符合独立同分布,且均值为0方差为1。当序列足够长时,互相关项趋近于0。后者则是用一些更为可靠的方式,来使用周期性伪随机序列,实现类似于随机序列的效果。
常用的 PN 序列类型:
- 最大长度序列(m-sequences):具有最长周期的线性反馈移位寄存器生成的序列。
- Gold 序列:通过两个 m-sequences 组合生成,具有良好的相关性特性。
- Kasami 序列:另一种伪随机序列,适用于特定的应用场景。
- …
最大长度序列 M sequences
线性反馈移位寄存器 LFSR
LFSR是一种通过线性递推关系生成序列的电路结构。
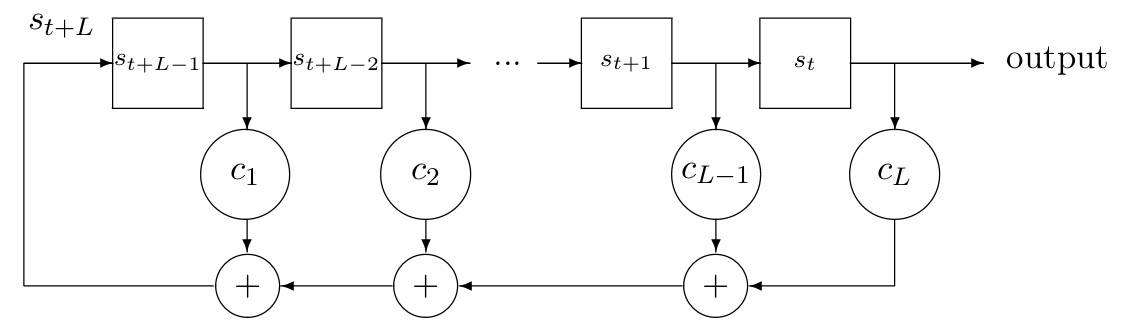
系统在下一时刻的状态,都取决于除该寄存器之外的寄存器的状态。
\[ s_{t+L}=\sum_{i=1}^L c_i s_{t+L-i}=c_0 s_n+c_1 s_{n+1}+\cdots+c_{L-1} s_{n+L-1} \]
由此可以定义特征多项式characteristic polynomial和反馈多项式feedback polynomial
:
\[ c_0+c_1 x+\cdots+c_{L-1} x^{L-1}+x^L\\c_0 x^L+c_1 x^{L-1}+\cdots+c_{L-1} x+1 \]
最大长度序列法即为使用一个LRSR结构生成一个具有最大长度的序列。如对于以下LFSR:
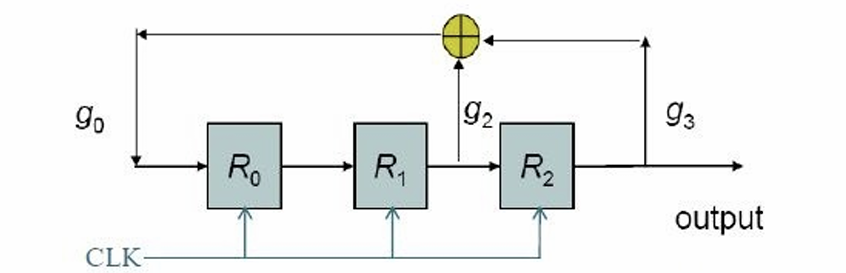
假设初始状态为\((1,0,0)\),即\(R_0 = 1,R_1 = 0,R_2 = 0\)。第一次更新,可得新的状态为\((0,1,0)\),因为\(R_{0,i = 1} = R_1+R_2, R_{1,i = 1} = R_0,R_{2,i = 1} = R_1\)。依次重复更新,即可发现最终将形成以为周期为\(7 = 2^3-1\)的循环。
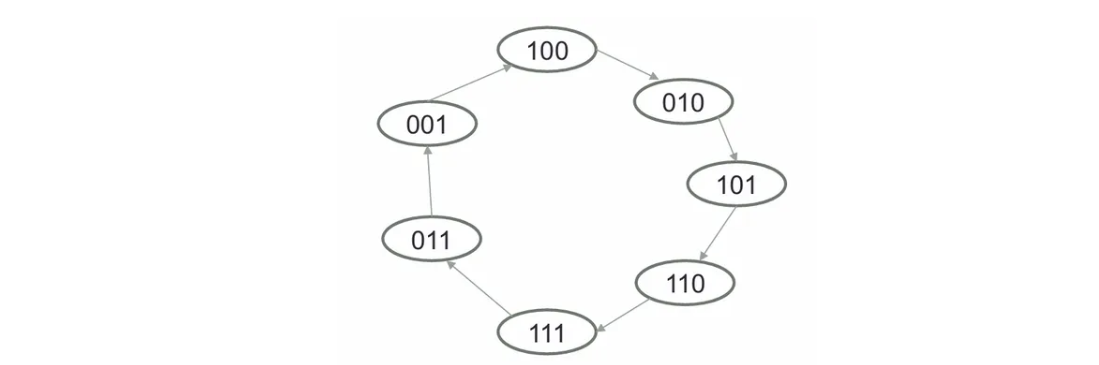
选择\(R_2\)的值作为最大长度序列\(0010111\)。在实际使用时将\(0\)替换为\(1\),将\(1\)替换为\(-1\)。
对于此最大长度序列,选择不同的延迟,可以得到\(7\)个不同的位移版本,对应\(7\)个编码:

这个编码具备性质,任意两个编码的加和是另一个编码。注意这里的和指的是01序列的\(\oplus\),也可以理解为1-1序列的对位相乘。根据这个性质,我们可以计算自相关:
\[ C^i_0\cdot C^i_{n} = \sum_{l=0}^{L-1} c_l^i c_{l-n}^i \]
无论\(n\ne0\)的取值,由于两个编码的积总是另一个编码,最终其实就是某一个编码的总和。在上述例子中,所有的编码都有三个1和四个-1,因此相关性等于\(-1\)。因此,我们有:
\[ \frac{1}{L} \sum_{i=0}^{L-1} c_l^i c_l^i=1,\frac{1}{L} \sum_{i=0}^{L-1} c_l^i c_{l-n}^i=\frac{-1}{2^m-1} \]
第二项相比于第一项是可忽略的,因此同一用户之间的干扰intersymbol interference可以忽略。
对于用户之间的干扰,由于编码是同一个序列的不同位移版本,所以两个序列可能会重合,\(\frac{1}{L} \sum_{i=0}^{L-1} c_l^i c_{l-n}^j\)可能会很高。
一个潜在的解决方案是为每个用户分配由不同m序列生成的码。
Glod序列
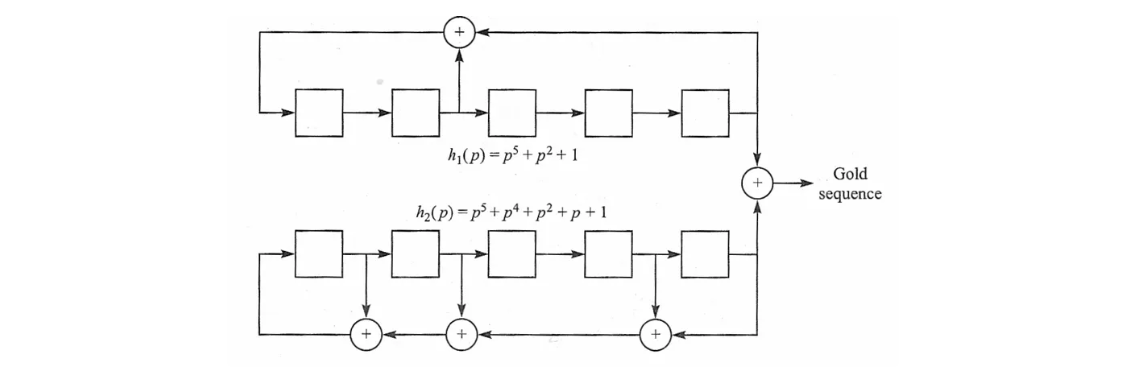
m序列具有良好的自相关性,但交叉相关性较大。交叉相关性被定义为:
\[ \mathrm{R}(t)=\sum_{i=0}^{L-1} c_l^i c_{l-n}^j = C^i_0\cdot C^j_n \]
Gold和Kasami证明了,存在某些m序列对,其交叉相关函数取值为\(\{-1,-t(m), t(m)-2\}\),其中:
\[ t(m)= \begin{cases}2^{(m+1) / 2}+1, & \text { 当 } m \text { 为奇数时 } \\ 2^{(m+2) / 2}+1, & \text { 当 } m \text { 为偶数时 }\end{cases} \]
这些m序列被称为优选序列(Preferred Sequences)。Gold序列就是两个优选序列的组合,具备与优选序列相同的交叉相关特性。
具体来说,Gold序列是通过两个不同移位/延迟的首选m序列的模2和生成的。
模2和(Modulo-2 Addition)是一种二进制运算,与按位异或(XOR)操作相同。
Gold序列的总数是 \(2^m + 1\):
- 包括两个独立的m序列,以及由不同移位值生成的 \(2^m - 1\) 个序列。
在3G中的实现:联合正交码和PN码
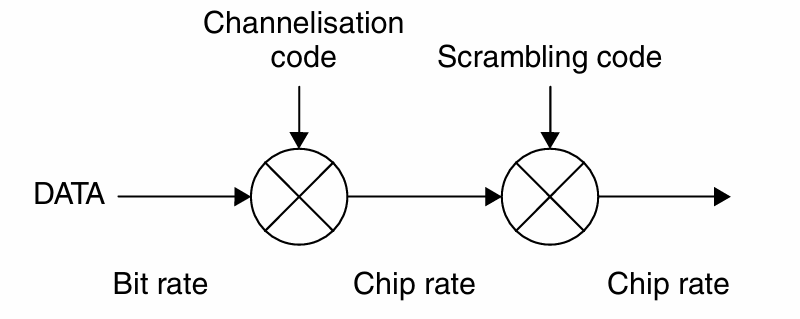
正交码
- 使用Walsh-Hadamard(采用OVSF码树)生成。
- 在连接期间,正交码可能会发生变化。
PN码(扰码)
- 每个小区在下行链路中分配一个特定的码。
- 每个用户在上行链路中分配一个特定的码。



