
熵和霍夫曼编码
熵和霍夫曼编码
编码
编码的目的是表示一系列符号 (\(s_n\)),其中 \(s_n\) 取自有限集合 𝒳。
- 这些符号可以是字母(文本编码)、整数(图像像素值)、音频信号的样本等。需要编码的符号类型并不重要。假设我们知道每个符号的出现概率,并且这些符号是独立生成的。每个符号由其代码表示,代码是一系列位(0或1),其长度可能可变。符号序列通过各个符号代码的串联来表示。
- 若编码操作是单射的,则称该编码是可解码
déchiffrable的。- 称一个编码为前缀码
code préfixe,当且仅当没有一个编码是另一个编码的前缀。这是编码可解码的充分条件。- 记编码为 \(φ\),其长度 \(|φ|\) 表达如下:\(|\phi|=\sum_{k=1}^K p_k\left|\phi\left(x_k\right)\right|\) 其中,\(p_k\) 是符号 \(x_k\) 的出现概率,\(|φ(x_k)|\) 是与符号相关的代码字长度。
现存的编码
布莱叶编码(Code Braille)
为了让盲人能够阅读,布莱叶编码用 6 个点(6 位)来表示字母。
莫尔斯电码(Code Morse)
莫尔斯电码通过点和划的序列以及空格来表示字母。可以通过编码将其转换为二进制,点用 1 表示,划用 111 表示(遵循莫尔斯电码的定义),点与划之间用 0 表示,字母之间用 00 表示,单词之间用 000 表示。
ASCII 编码(Code ASCII)
在 ASCII 编码中,字符通过 7 位的序列表示,这足以涵盖大写字母、小写字母、符号和控制字符。
为了编码英语以外的语言所需的字符(如重音符等),存在扩展至 8 位的版本,例如 ISO 8859-15,可用于法语。
UTF-8
Unicode 标准(截至 2023 年)包含 149813 个字符,允许编码大量的字母、特殊字符、表情符号等。UTF-8 编码能够表示这些字符。
编码一个字符所需的位数是可变的,范围为 8 到 32 位。ASCII 编码的字符(西方最常用的)使用 8 位编码,而更罕见的字符则使用更多的位数。
整数的二进制表示(Écriture binaire des entiers)
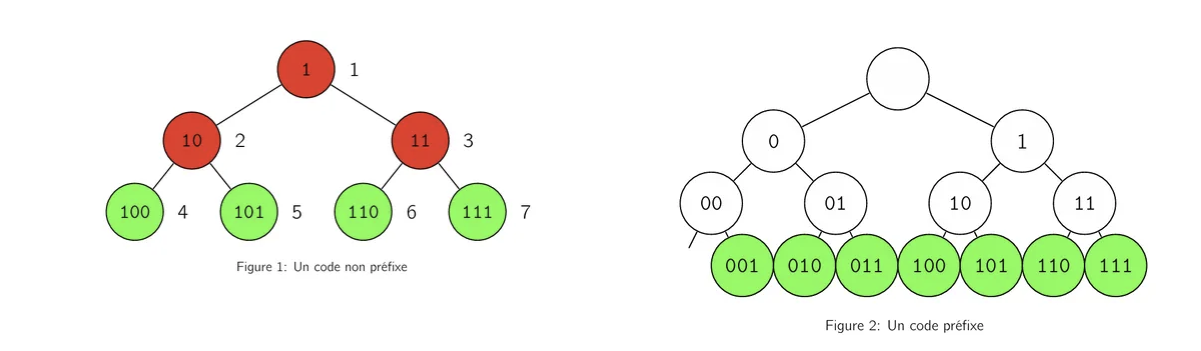
将 1 到 7 的整数通过其二进制表示编码如图 1 所示。这是一个非前缀码。例如,位序列 101 可以同时表示 (5) 或 (2, 1)。图 2 所示的编码是前缀码(所有等长的编码都是前缀码)。可以通过编码 1 为 00 来简化该编码。整数的编码不一定对应于其二进制表示。
最优编码
在这一节,我们的目的是构建一个最优编码,即最小化编码长度的编码,其定义为:
\[ |\phi|=\sum_{k=1}^K p_k |\phi\left(x_k\right)| \]
即我们要在编码为前缀码的约束下,找到一个长度集合\(l_k = \left|\phi\left(x_k\right)\right|\),满足:
\[ \min _{\left(l_k\right) \in \mathbb{N}^K}|\phi|=\sum_{k=1}^K p_k l_k,s.c. \ préfixw \]
处理此问题的第一步是将前缀码的约束替换为对其长度的约束。
克拉夫特-麦克米伦定理 Théorème de Kraft-McMillan
定理:对于一组长度为(\(l_k\))编码为前缀码,当且仅当以下条件成立时,前缀码满足:
\[ \sum_{k=1}^K 2^{-l_k} \leq 1 \]
证明:
正向:通过向下延展每个节点的叶子到最大编码长度 \(L\) 来补全树。每个节点编码的叶子数为 \(2^{L-l_k}\) 。由于是前缀码,不同节点的叶子集合互不相交,因此最多有 \(2^L\) 叶子。于是有:
\[ \sum_{k=1}^K 2^{L-l_k} \leq 2^L \]
两边除以 \(2^L\) ,得:
\[ \sum_{k=1}^K 2^{-l_k} \leq 1 \]
结论成立。
反向:从一个长度为 \(L\) 的完全二叉树出发,假设长度按降序排列。对于每个长度 \(l_k\) ,移除 \(2^{l_k}\) 个叶子,并将这些叶子分配给对应长度的父节点(长度按降序,每组叶子属于同一子树)。当叶子数量足够时,即满足:
\[ \sum_{k=1}^K 2^{L-l_k} \leq 2^L \]
这种构造是可能的。
根据克拉夫特-麦克米伦定理,原本的问题转化为:
\[ \begin{aligned}H= & \min _{\left(l_k\right) \in \mathrm{R}^K} \sum_{k=1}^K p_k l_k ,s.c. & \sum_{k=1}^K 2^{-l_k} \leq 1\end{aligned} \]
这是一个型如:
\[ \begin{gathered} \min f(x) , \text { s.c. } g(x) \leq 0 \end{gathered} \]
的问题。局部最优解\(x^*\)满足以下条件:
- \(\nabla f\left(x^{\star}\right)+\lambda \nabla g\left(x^{\star}\right)=0\)
- \(g\left(x^{\star}\right) \leq 0\)
- \(\lambda \geq 0\)
- \(\lambda g\left(x^{\star}\right)=0\)
根据这些条件,可得对于任意的\(k\):
\[ p_k-\lambda(\log 2) 2^{-l_k}=0 \]
解得:
\[ \lambda=\frac{1}{\log 2}, \quad l_k=-\log _2 p_k \]
于是有:
\[ H=\sum_{k=1}^K p_k l_k=-\sum_{k=1}^K p_k \log _2 p_k \]
\(H\)是离散概率分布\((p_k)_k\)的熵。
若符号集合均匀分布,\(p_k = 1/K\),则有 \(H = log_2K\)
长度 \(l_k\) 可以取实数,因此比原问题中的整数约束更宽松。最优编码长度 \(L^{\star}\) 满足以下关系:
\[ H \leq L^{\star} \]
反过来,存在一个前缀码(Shannon 编码) \(\phi^{\dagger}\) 的长度为 \(l_k^{\dagger}=\left\lceil l_k\right\rceil\) ,满足:
\[ L^{\dagger}<H+1 \]
虽然这不一定是最优编码,但保证了最优编码长度 \(L^{\star}\) 满足如下界限:
\[ H \leq L^{\star}<H+1 \]
霍夫曼编码:构建最优编码
前一部分确认了存在一个长度不超过\(H+1\)的最优编码,但未提供其构造方法。霍夫曼算法能够保证构造出一个最优编码。
霍夫曼算法
霍夫曼算法以递归方式构建编码 \(\phi\) 。它接收符号列表 \(\left(x_1, \ldots, x_K\right)\) 及其对应的概率 \(\left(p_1, \ldots, p_K\right)\) 作为输入。
当 \(K=2\) 时,给两个符号 \(\left(a_1, a_2\right)\) 分配编码:
\[ \phi\left(a_1\right)=0, \quad \phi\left(a_2\right)=1 \]
当 \(K>2\) 时,假设符号 \(\left(a_1, \ldots, a_K\right)\) 按概率降序排列 \(\left(p_1, \ldots, p_{K-1}, p_K\right)\) 。将符号 \(\left(a_{K-1}, a_K\right)\) 合并为一个新符号 \(z\) ,其概率为 \(p_{K-1}+p_K\) 。对于新符号集合 \(\left(a_1, \ldots, a_{K-2}, z\right)\) 构建霍夫曼编码 \(\phi^{\star}\) 。然后设置:
\[ \phi\left(a_k\right)=\phi^{\star}\left(a_k\right) \text { (对于 } k \leq K-2 \text { ), } \phi\left(a_{K-1}\right)=\phi^{\star}(z) 0, \quad \phi\left(a_K\right)=\phi^{\star}(z) 1 \]
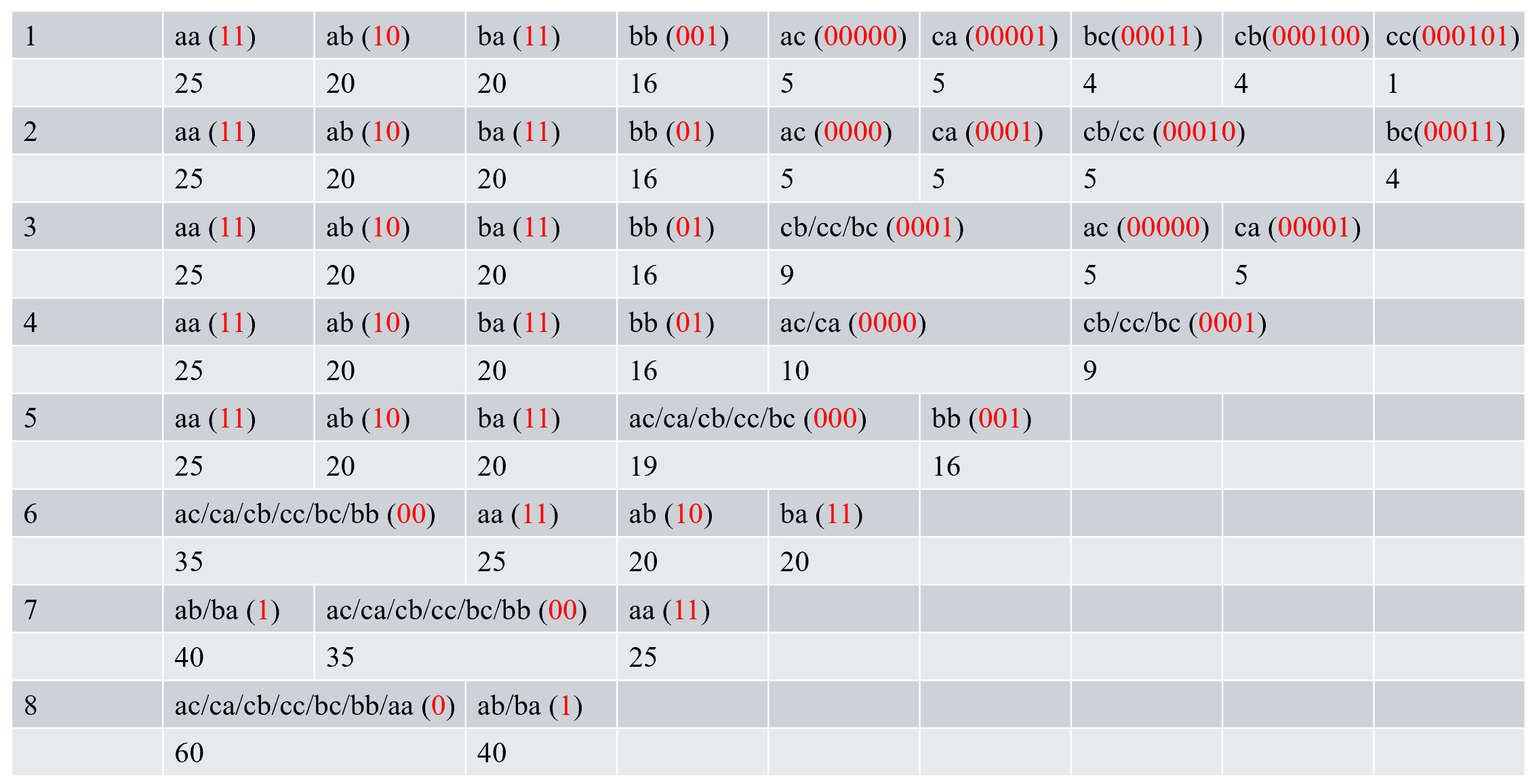
例如
最优性证明
引理:对于一组给定的符号及其概率,总可以找到一个最优编码,使得概率最小的两个符号是兄弟节点。
证明:
- 假设 \(x\) 和 \(y\) 是概率最小的两个符号,但它们不是兄弟节点。如果它们位于同一深度的不同分支,可以交换分支,使其成为兄弟节点,而不改变编码长度。于是存在一个满足条件的最优编码。
- 假设 \(l_x>l_y\) 。如果 \(x\) 没有兄弟节点,可以将其上移一层,此时编码不是最优的。如果 \(x\) 有兄弟节点(符号或子树),则可以将其与 \(y\) 交换,从而减少编码长度。唯一的可能是 \(x\) 和 \(y\) 作为兄弟节点,并具有相同的长度,从而保留最优性。
通过递归证明。当 \(K=2\) 时,结论显然成立。 假设对于 \(K-1\) 个符号结论成立。霍夫曼算法为 \(K\) 个符号生成了编码 \(\phi_K\) 。同时,存在一个满足最优条件的编码 \(\psi_K\) 。在这两种情况下,符号 \(x\) 和 \(y\) 是兄弟节点(即它们的编码长度相同)。通过将这两个符号在 \(\phi_K\) 中合并为一个符号 \(z\) ,可以得到 \(K-1\) 个符号的霍夫曼编码 \(\phi_{K-1}\) 。同样,在最优编码 \(\psi_K\) 中进行合并,也可以得到 \(K-1\) 个符号的编码 \(\psi_{K-1}\) 。对于这两种情况,有以下等式成立:
\[ \begin{aligned} & \left|\phi_K\right|=\left|\phi_{K-1}\right|+p_x+p_y \\ & \left|\psi_K\right|=\left|\psi_{K-1}\right|+p_x+p_y \end{aligned} \]
由此可得:
\[ \left|\phi_K\right|=\left|\phi_{K-1}\right|+p_x+p_y, \quad\left|\psi_K\right|=\left|\psi_{K-1}\right|+p_x+p_y \]
实际上, \(K\) 个符号的编码是通过向 \(z\) 的编码添加一个比特来重新找到 \(x\) 和 \(y\) 的编码,这在平均意义上增加了 \(p_x+p_y\) 的长度。
由于对于 \(K-1\) 个符号的霍夫曼编码是最优的,得出:
\[ \left|\phi_{K-1}\right| \leq\left|\psi_{K-1}\right| \]
从而可以推导出:
\[ \left|\psi_K\right| \leq\left|\phi_K\right| \leq\left|\psi_K\right| \]
这证明了霍夫曼算法对 \(K\) 个符号的最优性。
基于块的霍夫曼编码
为了更接近熵,可以对符号块进行编码,而不是单独对每个符号编码。此时,每个符号的平均长度上限为:
\[ H+\frac{1}{N} \]
\(N\)是块的长度
局限性
霍夫曼编码的局限性包括以下需求:
- 必须知道符号的概率。
- 必须传递编码信息。
- 或者必须传递概率信息。
- 或者必须预先固定编码(例如,在某些压缩标准中)。
其他编码方法:
算术编码(Code arithmétique)
这种方法可以在不需要构造块(因此避免代码复杂性随块大小增长而增加)的情况下达到理论压缩界限。
Lempel-Ziv 编码
一种基于字典的编码方法,将符号流分割为由先前观察到的序列和符号组成的片段。它还可以达到压缩界限,并能考虑符号间的相关性。
PNG 格式
PNG 格式是一种无损压缩的图像存储格式。像素通常通过 8 位或 16 位表示,支持 1 至 4 个通道(灰度、RGB、透明度)。
算法的两个步骤包括:
- 预测步骤:用于降低熵。
- DEFALTE 编码:结合 Lempel-Ziv 和霍夫曼编码的方法。
不同的预测方法
可以使用以下几种预测方法:
- 0:无过滤,直接编码原始像素强度值。
- 1:编码当前像素与像素 A 的差值。
- 2:编码当前像素与像素 B 的差值。
- 3:编码当前像素与像素 A 和 B 平均值(向下取整)的差值。
- 4:编码当前像素与 A、B 或 C 中最接近 \(A+B−C\) 值的像素的差值。
其中,预测方法对每一行是固定的。



