
Chapter 9 Transformers
Chapter 9 Transformers
由于文本生成不是我的主要学习目的,本章学习不会尝试使用PyTorch复现。另一个原因是Diffusion的PyTorch版主直到本章开始学习都不能正常工作。考虑到目前对一些知识还处于一知半解的状态,且我的学习目的也并非实现Diffusion或者GPT这些网络,故暂时不会进行使用PyTorch的重现。
尽管如此,我还是在原文提供的GPT上进行一些“随心所欲”,或者说“完全不知道原理只是瞎改”的,修改。尽管我现在还有得到结果,但可以预料到势必会导致表现变差。
PyTorch的重现已经添加,基本架构相同,只是作用在另一个任务上。

介绍
Transformer神经网络是一种不需要循环或者卷积架构,依赖于注意力机制的神经网络。是目前用于文本生成的最重要的架构。GPT全程Generative Pre-Training是一种能够在大量文本数据上训练的Transformer架构。在预训练期间,模型被训练为在给定先前单词的情况下预测序列中的下一个单词。此过程称为语言建模,用于教导模型理解自然语言的结构和模式。预训练后,可以通过为 GPT 模型提供更小的、特定于任务的数据集来针对特定任务进行微调。
数据集
原书使用了Wine Reviews Dataset。这个数据集包含了超过13万条葡萄酒评论,其中包括了品种、产地、酒庄、价格和描述等信息。
GPT
在本章中,我们将构建和了解我们自己的原始 GPT 模型的变体,使用较少的数据进行训练,但仍然利用相同的组件和基本原理
注意力机制Attention
注意力机制使得 Transformer 架构独一无二,并且与语言建模的循环方法截然不同。
与之前我们讨论过的文字生成模型相似,句子的下一个单词的选择会受到前面所有单词的影响。
我们可以猜测到下一个词可能是big。但是作为一个人,我们是根据哪些单词猜到的下一个词是big
呢?elephant
和car可能是相比于pink等单词更为重要。换句话说,我们更多的注意到句子中的某些单词,而忽略了另外一些单词。
Transformer 中的注意力机制(也称为注意力头attention head)就是为了做到这一点而设计的。它能够决定要从输入中的何处提取信息,以便有效地提取有用的信息。
查询Queries, 键Keys, 值Values
为了完成这项任务,我们为每个单词赋予一个类似于“信心”的属性。使得elephant这个单词对自己更加自信,以为下一个单词提供更多的信息;而was则对自己信心较少,以为下一个单词提供更少的信息。
换句话说,我们可以将注意力头理解为一种信息查询机制。下一个单词是什么这个问题被引入到一个键值对存储系统。由查询Q与每一个键K的共振resonance决定权重,最终的预测结果为值V得加权求和。如下图所示。
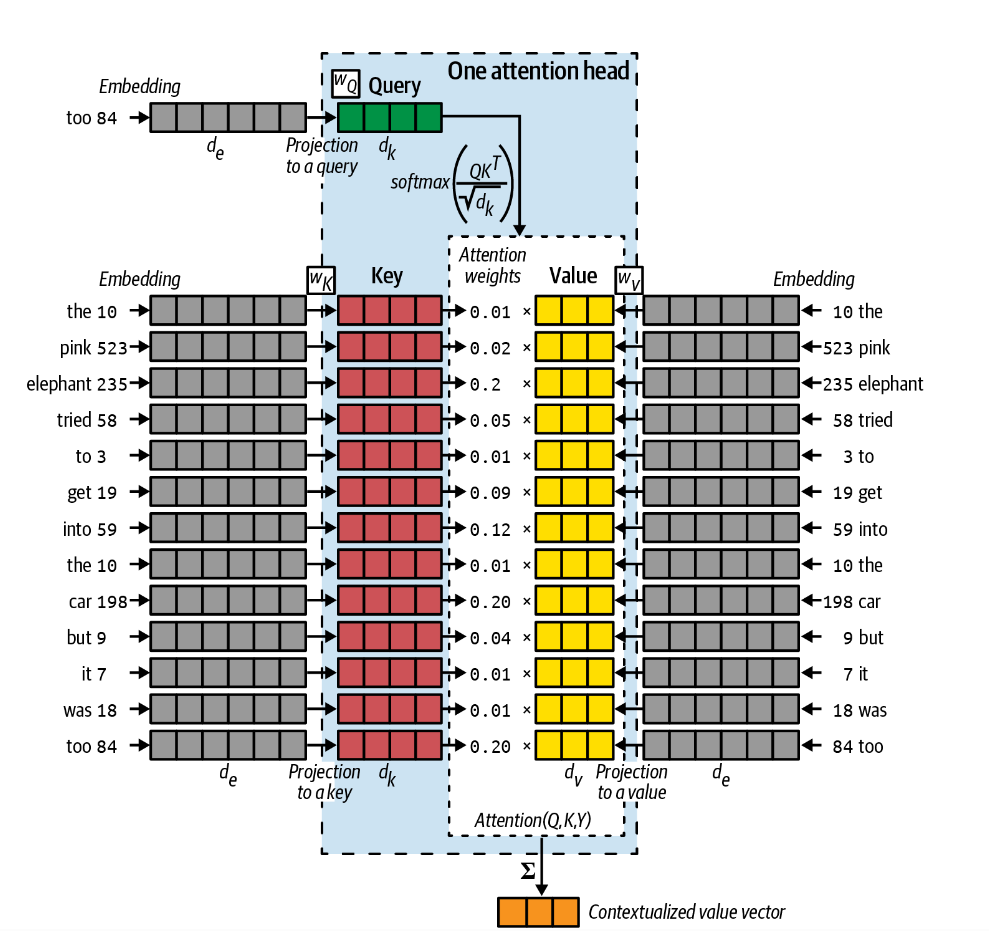
查询向量Q是当前任务得一种表示。如再训练过程中,我们得任务就是简单的预测下一个单词。在上面得例子中,它是一个单词too,与其他单词得输入方式一致,在编码后传递给权重矩阵\(W_Q\)转换为一个\(d_k\)长度的向量\(Q\)。
键向量K是句子中每个单词的表示,再编码后经过权重矩阵\(W_K\),每一个K都转换为一个\(d_k\)的向量\(K\)。这与查询的向量长度相同。
再注意力头中,使用点积计算权重;按照d_k缩放以保证方差稳定;最终经过softmax以保证总和为1:
\[ w_i = softmax(\frac{v_k\cdot v_q}{\sqrt{d_k}})= softmax(\frac{Q\cdot K^T}{\sqrt{d_k}}) \]
值向量V也是句子中单词的表示,可以将它们视为每个单词的未加权贡献。也经过权重矩阵\(W_V\)转化为一个\(d_k\)的向量\(V\)。但是值向量不一定必须与键和查询具有相同的长度,只是为了简单起见,通常这样做。
由此,注意力attention被定义为:
\[ \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V \]
为了从注意力头获得最终的输出向量,注意力被求和以给出长度为 \(d_v\) 的向量。该上下文向量捕获了句子中单词的混合意见,以预测接下来的单词。
多注意力头 Multihead Attention
将多个注意力头的输出连接在一起,可以得到一个Multihead Attention。
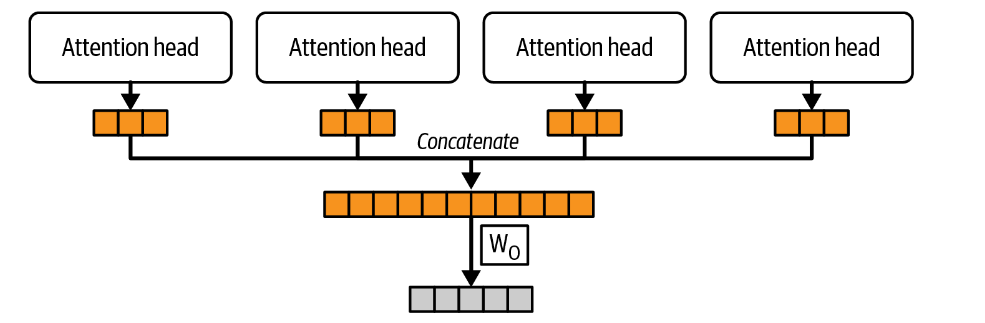
连接的输出通过一个最终权重矩阵 \(W_O\) 传递,将向量投影到所需的输出维度。
在Keras中可以直接使用tf.keras.layers.MultiHeadAttention
来定义。而在PyTorch中,也可以使用torch.nn.MultiheadAttention
来定义。
它们的文档可以在如下两个连接中找到。
MultiheadAttention — PyTorch 2.1 documentation
tf.keras.layers.MultiHeadAttention | TensorFlow v2.15.0.post1
因果掩蔽 Causal Masking
之前的模型中,我们假设了输入是一个单词too
,我们希望注意力层能同时对输入的每一个单词进行操作,即希望GPT能并行处理一组查询向量。
在直接将向量一起处理成一个矩阵之前,我们需要一个额外的步骤:对查询-键点积应用掩蔽,以避免未来单词的信息泄漏。在计算注意力分数时,我们不能见到当前单词之后的单词。比如,我们希望在预测it之后的单词时,was和to时不可见的。
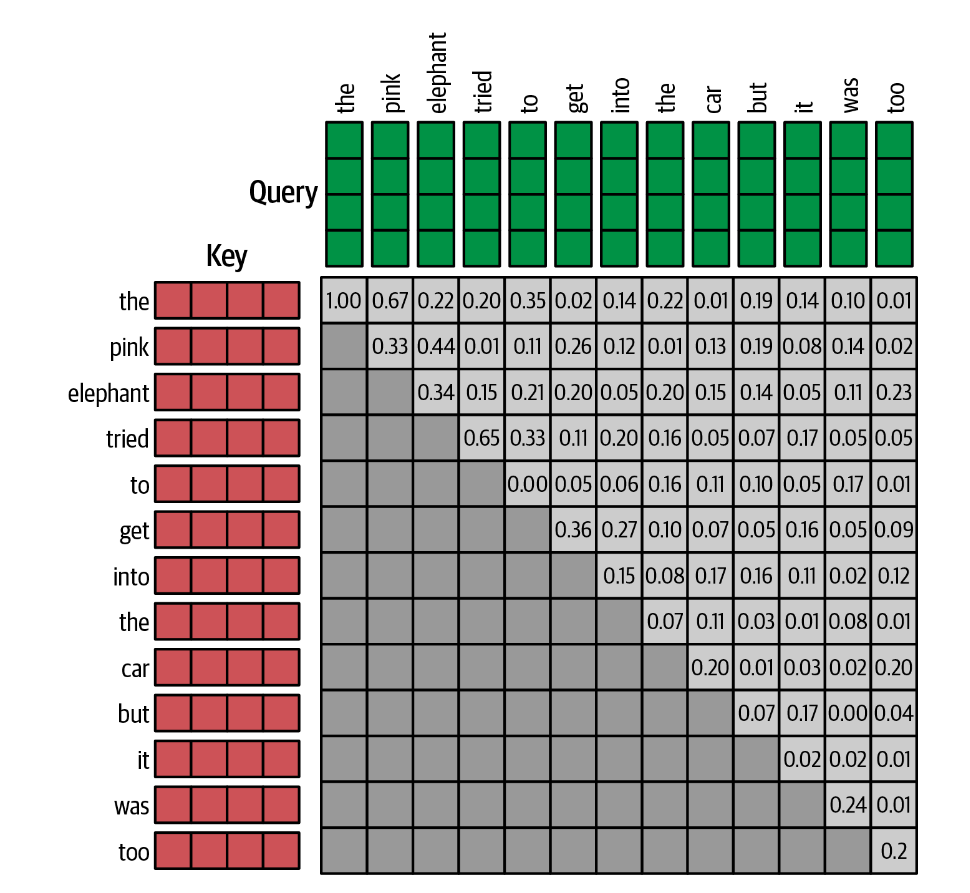
这种掩蔽层我们曾经创建过类似的,在Keras中,我们可以将其定义为:
1 | def causal_attention_mask(batch_size, n_dest, n_src, dtype): |
其中, m 是一个布尔矩阵,如果 i
中的元素大于等于 j 中的元素减去 n_src 加上
n_dest,则对应位置为 True,否则为
False。这个矩阵的形状为
(n_dest, n_src),表示在位置 i
是否可以关注到位置 j。
如果使用PyTorch实现这个函数,可以将尝试使用torch.triu函数。
torch.triu — PyTorch 2.1 documentation
值得注意的是,这样一个有影响力的层的可学习参数只不过是由每个注意力头的三个密集连接的权重矩阵(\(W_Q\)、\(W_K\)、\(W_V\))和另一个用于重塑输出的权重矩阵(\(W_O\))组成。
Transformer Block
Transformer 块是 Transformer 中的单个组件,它应用一些跳跃连接、前馈(密集)层和围绕多头注意力层的归一化。
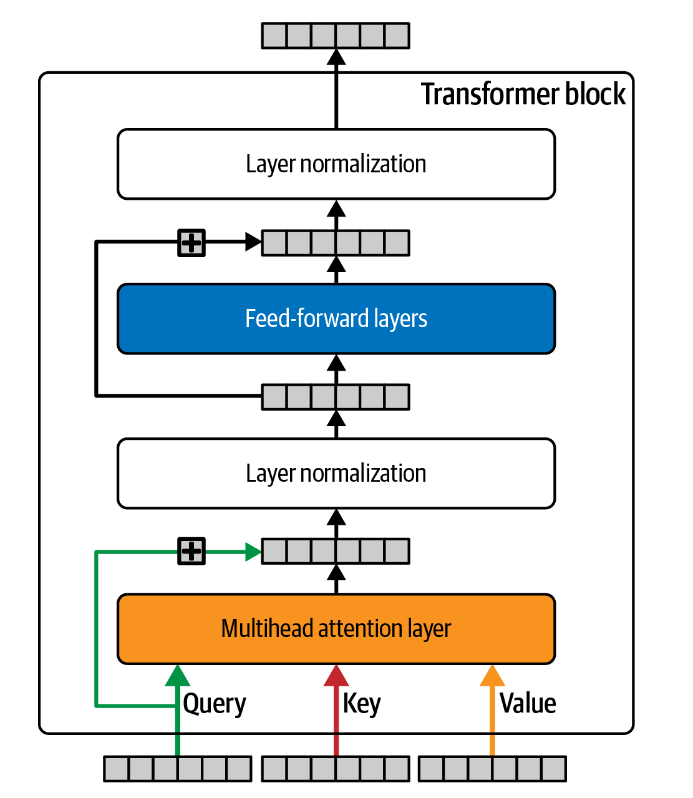
层归一化 layer normalization
层归一化对批次中每个序列的同一位置进行跨通道的归一化。
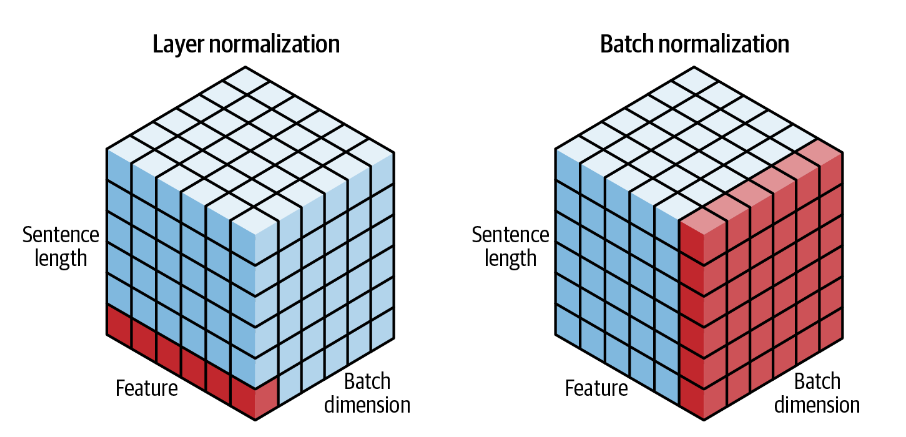
在Keras中可以通过tf.keras.layers.LayerNormalization
实现,而在PyTorch中可以通过torch.nn.LayerNorm 实现。
LayerNorm — PyTorch 2.1 documentation
tf.keras.layers.LayerNormalization | TensorFlow v2.15.0.post1
构建Transformer Block
在Keras中,如下定义Transformer Block块:
1 | class TransformerBlock(layers.Layer): |
位置编码 Positional Encoding
现在的GPT模型中没有任何机制能够区分输入的顺序。因此注意力层不能分辨以下两句话。
The dog looked at the boy and ... (barked?)The boy looked at the dog and ... (smiled?)
因此,我们在创建Transfomer块时使用位置编码技术。如此,我们不仅使用token embedding对字符进行编码,还要使用position embedding对位置进行编码。我们同样使用一个embedding层实现,并于token embedding结合构成token–position encoding。
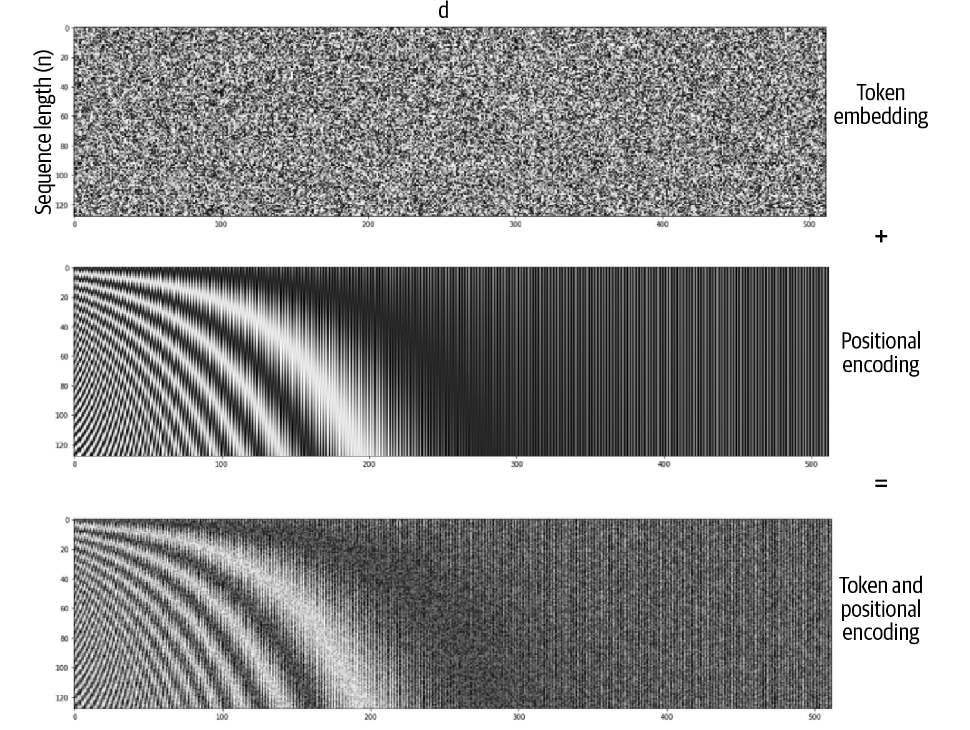
1 | class TokenAndPositionEmbedding(layers.Layer): |
模型训练
构建网络
我们构建一个仅包括一个transformer块的网络
1 | inputs = layers.Input(shape=(None,), dtype=tf.int32) |
使用adam优化器和交叉熵损失(在torch中被定义为torch.nn.CrossEntropyLoss
)开始训练。
结果分析
总体来看,结果相比于之前的使用lstm实现的效果好许多。以下是输入为:水 调 歌 头 : 明 月 几 时 有 ,
时生成的词的下半阙和下半阙的第一句。
1 | 水 调 歌 头 |
它很不错的完成了格律和局部的语义连贯,很值得赞叹。这一部分唯一的不正确的格律为雾和应两字。
以下是部分有意思的细节。
对句号位置的把控 模型似乎可以很好的把控句号的位置,使得尽管有时逗号的位置不对,但每一句话的长度正确率较高。这可能部分词的变体导致逗号位置不固定引入的问题。
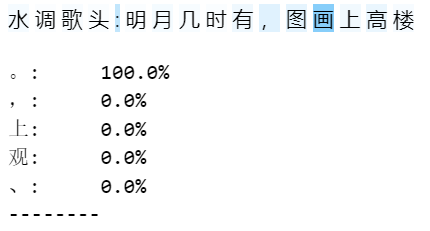

对韵脚的把控
模型似乎能正确的根据韵脚填词,比如在填钩和休时,楼的权重都很大。





