
Chapter 5 Autoregressive Models 自回归模型
Chapter 5 Autoregressive Models 自回归模型
在本章中,我们将探讨两种自回归模型,LSTM ~~Literary Society for Troublesome Miscreants~~ long short-term memory networks 和 PixelCNN,而另一种非常成功的自回归模型transformer会在之后的内容中提到。

Long Short-Term Memory Network (LSTM)
介绍
流氓文学会
RNN
RNN包含一个循环层(或单元),它能够通过使自己在特定时间步长的输出成为下一个时间步长输入的一部分来处理顺序数据。以下是一个基本的RNN程序。
1 | class BasicRNN(nn.Module): |
这个模型相比于简单的多层感知机最主要的区别是隐藏状态hidden。可以注意到,在forward时需要输入hidden,这是在时间步之间传递的状态。在每个时间步,RNN都会根据当前的输入和前一个时间步的隐藏状态来更新其隐藏状态。这使得RNN能够在处理序列数据时,记住或"理解"过去的信息。
文字数据处理方法
文字数据的特殊性
文字数据和图像数据有很多不同,我们需要额外的设计来使得其能够被正确处理
- 文本数据时离散的字符或单词组成,我们知道如何通过改变某些数据使得绿色转化为蓝色,但我们不知道如何简单的将green转化为blue。则使得我们不能简单的反向传播。
- 文本数据具有时间维度但没有空间维度,文字的上下文信息非常重要。
- 文本数据对微小变化十分敏感
- 文本数据有基于语法的基本结构
符号化
一般来说,符号化包括单词标记word token和字符标记character token。
使用单词标记:
- 所有无特殊含义的文本都可以转换为小写,以确保句子开头的大写单词与句子中间出现的相同单词以相同的方式标记
- 用未知单词的标记替换稀疏单词,而不是将它们作为单独的标记,以减少神经网络需要学习的权重数量
- 单词可以被词干化,这意味着它们被简化为最简单的形式
- 标记标点符号,或者将其完全删除
- 使用单词标记化意味着该模型将永远无法预测训练词汇之外的单词
使用字符标记:
- 可以生成在训练词汇表之外形成新词的字符序列,尽管可能并不正确
- 大写字母可以转换为小写字母,也可以保留为单独的标记
- 当使用字符标记化时,词汇量通常要小得多,这有利于模型训练速度
代码实现
在这里我尝试在另一个中文的数据集chinese-poetry上实现LSTM。由于我之前未处理过文字数据,可能存在错误。
建立训练集
按照我的理解,数据集最终应该是一个类似于二维整数数组的数据结构。使用PyTorch实现这一部分。继承Dataset类。解释见注释。
1 | class PoetryDataSet(Dataset): |
LSTM结构
模型的结构非常简单
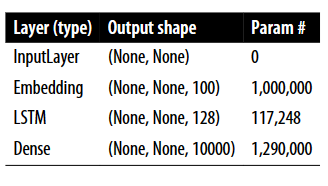
左图为原书提供的LSTM的结构,使用PyTorch重现的模型如下:
1 | class LSTMModel(nn.Module): |
embedding层 embedding层主要用于处理具有大量类别的离散数据。由于较大的类别数量,one-hot编码的维度很高。embedding层将这些离散数据映射到一个连续的低维向量。这样不仅可以大大减少数据的维度,还可以使得在训练过程中,语义相近的单词在向量空间中的距离更近。
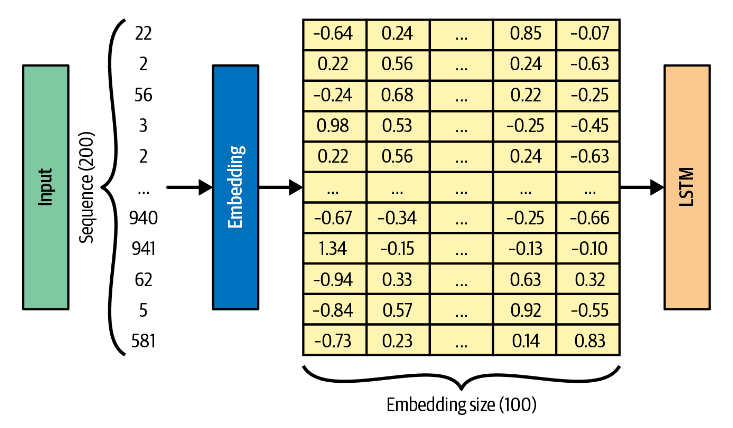
1 | class torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, _freeze=False, device=None, dtype=None) |
其中,num_embeddings是嵌入字典的大小,embedding_dim是每个嵌入向量的大小。输入该层的是一个索引列表,输出是相应的词嵌入。
LSTM层:LSTM是一种cell由LSTM cell替换的循环层recurrent layer。其工作原理如下所示。
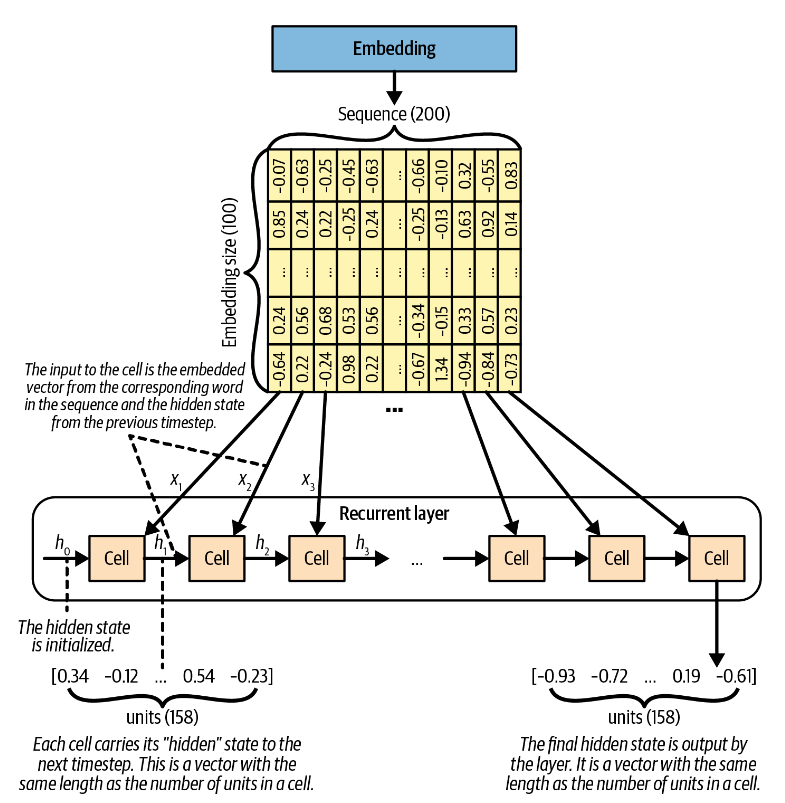
一句话经过embedding层之后,每个词转换为一个向量。这些向量以此被输入到同一个cell中(注意,图中的cell都是同一个cell),同时被输入的还有隐藏状态。由此,这些细胞会产生一个类似于根据最新单词和之前的工作成果预测下一个单词的效果。
LSTM Cell:LSTM单元的工作是给定其先前的隐藏状态ht-1和当前的单词嵌入xt,输出一个新的隐藏状态ht。ht的长度等于LSTM中的单元数量,我们可以在创建时指定隐藏状态的维度或者单元数量,这是等价的。
1 | keras.layers.LSTM(units, activation="tanh", recurrent_activation="sigmoid", use_bias=True, kernel_initializer="glorot_uniform", recurrent_initializer="orthogonal", bias_initializer="zeros", unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, seed=None, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False, **kwargs) |
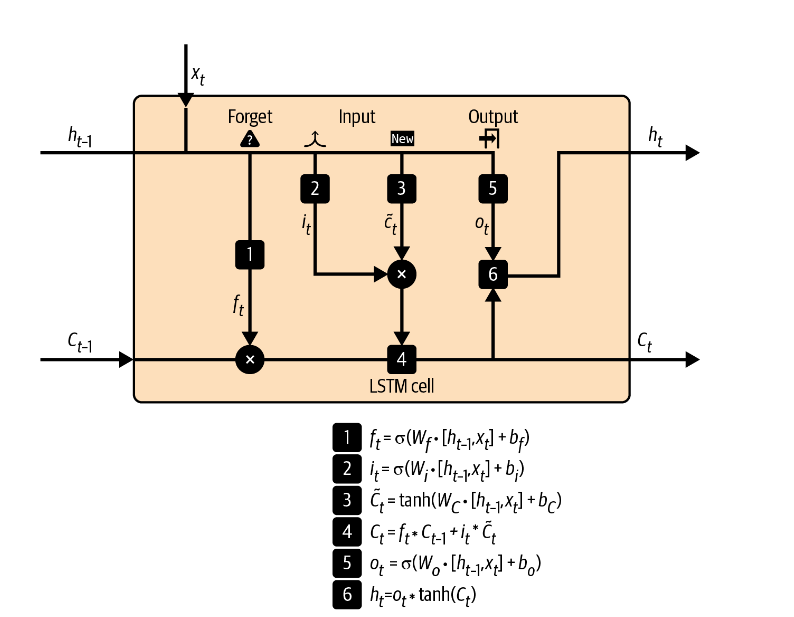
一个LSTM cell有以下四个部分组成
- 单元(Cell):这是LSTM的核心部分,用于存储跨越任意时间间隔的值。
- 输入门(Input Gate):决定哪些新的信息会被存储到当前的状态中。
- 遗忘门(Forget Gate):决定从前一个状态中丢弃哪些信息。它通过将前一个状态与当前输入进行比较,赋予一个介于0和1之间的值。1表示保留信息,0表示丢弃信息。
- 输出门(Output Gate):控制在当前状态中哪些信息会被输出。
根据特定的信息调节方式,信息从三个门进出单元,选择性的从当前状态中学习和输出相关信息,从而拥有了保持有用的长期依赖的能力。
模型训练
模型的训练过程并没有太多需要关注的部分,tensorflow中选择的损失函数是值得讨论的一点。
tensorflow的代码中使用了SparseCategoricalCrossentropy()
作为损失函数。据描述,这是一种用于计算稀疏离散问题的损失函数,主要作用是使用标签而非one-hot编码计算损失。而在PyTorch中,交叉熵函数本身的输入就是标签,因此我们不能找到一个特定的SparseCategoricalCrossentropy()
函数,而是可以直接使用torch.nn.CrossEntropyLoss()
作为损失函数。这是我之前不曾注意到的。
结果分析
时间原因,我并没有尝试运行原书代码,根据原书给出的实验结果,看起来效果不错。据原书自己描述,尽管我们的基本LSTM模型在生成真实文本方面做得很好,但很明显,它仍然很难理解所生成单词的一些语义。它引入了不太可能很好地搭配的成分(例如,酸日本土豆、山核桃屑和冰糕)。
而我实现的PyTorch的代码则损失函数下降速度很慢。这可能是因为古诗词本身比较复杂,和中文本身一词多义过于严重导致的。
Recurrent Neural Network (RNN) Extensions
我们来讨论几种上述的简单代码的优化方式。
堆叠循环网络
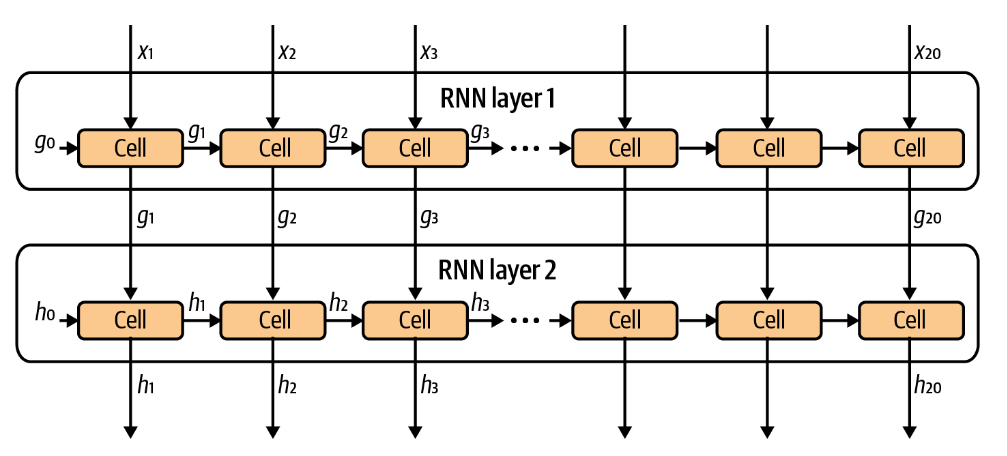
这个改进比较好实现。如果使用PyTorch实现,可以直接调节num_layers参数来堆叠LSTM层。而如果使用tensorflow实现,也可以直接如下所示堆叠。
1 | x = layers.LSTM(n_units, return_sequences = True)(x) |
Gated Recurrent Units
门控循环单元作用与LSTM功能上类似,有两个主要区别
- 输入门和遗忘门被替换为重设门和更新门
- 没有单元状态或输出门,只有从单元输出的隐藏状态。
Pytorch中可以使用torch.nn.GRU(),Keras中可以使用keras.layers.GRU()
双向单元 Bidirectional Cells
对于整个文本在推理时,都可供模型使用的预测问题,没有理由仅向前处理序列,也可以向后处理。双向层通过存储两组隐藏状态来利用这一点:一组是在通常的前向处理序列时产生的,另一组是在向后处理序列时产生的。
在keras中,可以这样实现:
1 | layer = layers.Bidirectional(layers.GRU(100)) |
在PyTorch中比较复杂,因为PyTorch并没有提供现成的bidirectional
,但可以使用类似下面的代码的方式控制处理方向。
1 | h0 = torch.zeros(self.num_layers*2 if self.bidirectional else self.num_layers, x.size(1), self.hidden_size).to(x.device) |
PixelCNN
接下来我们讨论PixelCNN,时间原因这一部分不使用PyTorch重现,仅在部分内容描述PyTorch的可能实现方式,但未必真的可以运行。日后如果有兴趣可能会尝试实现。
该模型通过根据下一个像素之前的像素预测下一个像素的可能性来逐像素生成图像。该模型称为 PixelCNN,可以训练它以自回归方式生成图像。
Masked Convolutional Layers 掩蔽卷积层
虽然普通的卷积层对于特征检测非常有用,但它们不能直接用于自回归意义上,因为没有对像素进行排序。它们依赖于这样一个事实:所有像素都被平等对待——没有像素被视为图像的开始或结束。
为了能够将卷积层应用于自回归意义上的图像生成,我们必须首先对像素进行排序,并确保卷积核只能看到相关像素之前的像素。一般我们采用从左上到右下的顺序。
在PixelCNN中,有两种掩蔽卷积层被使用:
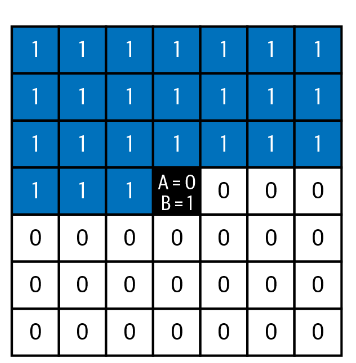
初始的掩模卷积层(即直接应用于输入图像的层)不能使用中心像素,因为这正是我们希望网络猜测的像素
后续层可以使用中心像素,因为这仅是根据原始输入图像中先前像素的信息来计算的
实现非常简单,使用Keras的实现可以直接参考原书代码。使用PyTorch的实现如下,原理相同。
1 | class MaskedConv2d(nn.Conv2d): |
Residual Blocks 残差块
输入有一条到输出的快速通道,无需经过中间层——这称为跳跃连接skip connection。

使用PyTorch可以类似于如下实现:
1 | class ResidualBlock(nn.Module): |
PixelCNN的训练
PixelCNN的结构
模型结构如下,包含了五个残差层,加上额外的掩蔽卷积和卷积。
模型结构
模型: "model"
| 层(类型) | 输出尺寸 | 参数数量 |
|---|---|---|
| input_1 (InputLayer) | (None, 16, 16, 1) | 0 |
| masked_conv2d (MaskedConv2D) | (None, 16, 16, 128) | 6400 |
| residual_block | (None, 16, 16, 128) | 53504 |
| residual_block_1 | (None, 16, 16, 128) | 53504 |
| residual_block_2 | (None, 16, 16, 128) | 53504 |
| residual_block_3 | (None, 16, 16, 128) | 53504 |
| residual_block_4 | (None, 16, 16, 128) | 53504 |
| masked_conv2d_6 (MaskedConv2D) | (None, 16, 16, 128) | 16512 |
| masked_conv2d_7 (MaskedConv2D) | (None, 16, 16, 128) | 16512 |
| conv2d (Conv2D) | (None, 16, 16, 1) | 129 |

具体的训练结果由于我没有实际训练这个模型,引用原书中的评价:该模型很好地再现了原始图像的整体形状和风格。
改进:混合分布 Mixture Distributions
我们将PixelCNN的输出减少到只有4个可用颜色级别,以确保网络不必学习256个独立颜色上的分布,这会减缓训练过程。然而,这远非理想——对于彩色图像,我们不希望我们的画布仅限于少数可能的颜色。为了解决这个问题,我们可以按照Salimans等人提出的想法,将网络的输出设为混合分布,而不是256个离散像素值上的softmax。
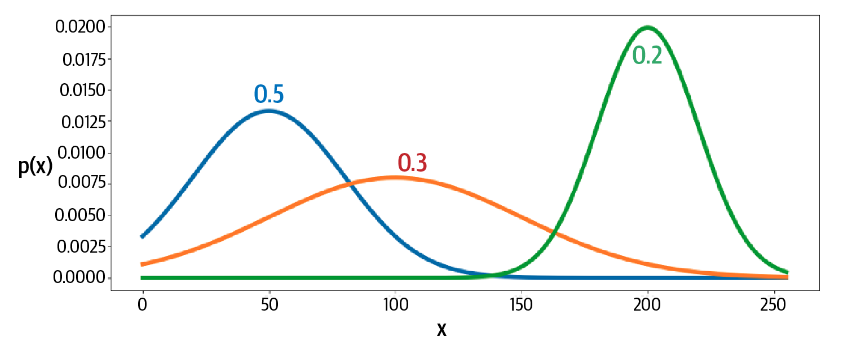
换言之,我们使用集中颜色的依概率混合来体现其他颜色。


