Chapter 4 Generative Adversarial Networks 生成对抗网络
GAN的介绍
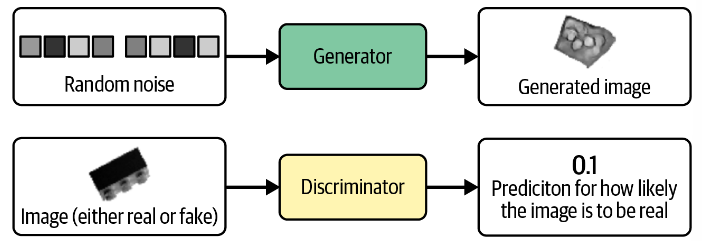
GAN包含两个部分生成器Generator 和判别器Discriminator 。生成器基于随机噪音生成图像,判别器判断生成器生成的图像是否为真实存在的图像。生成器的训练目的是尽可能生成判别器识别不出来的图像,而判别器的训练目的是尽可能区分生成器生成的图像和真实存在的图像。
Deep Convolutional GAN(DCGAN)
在这一部分,我们会跟随作者的步伐使用Keras构建一个DCGAN网络。同时我也会尝试使用PyTorch重现这些代码。
数据集
我们使用Images of LEGO Bricks dataset数据集。
数据集加载 Tensorflow的数据集加载方法包括使用image_dataset_from_directory的数据加载和使用preprocess函数的预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 train_data = utils.image_dataset_from_directory( "/app/data/lego-brick-images/dataset/" , labels=None , color_mode="grayscale" , image_size=(64 , 64 ), batch_size=128 , shuffle=True , seed=42 , interpolation="bilinear" , ) def preprocess (img ): img = (tf.cast(img, "float32" ) - 127.5 ) / 127.5 return img train = train_data.map (lambda x: preprocess(x))
使用Pytorch的数据集加载方式,在设计transform时需要考虑:
将图像尺寸加载为(64,64)
使用灰度图加载
使用ToTensor()调整数据范围到[0,1]
在使用Normalize((0.5,), (0.5,)) 调整数据范围为[-1,1]
1 2 3 4 5 6 7 8 9 10 11 12 13 preprocess = transforms.Compose([ transforms.Resize((64 , 64 )), transforms.Grayscale(), transforms.ToTensor(), transforms.Normalize((0.5 ,), (0.5 ,)) ]) train_data = datasets.ImageFolder(root="/app/data/lego-brick-images/dataset/" , transform=preprocess) train_loader = DataLoader(train_data, batch_size=128 , shuffle=True , num_workers=0 )
判别器 使用Tensorflow的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 discriminator_input = layers.Input(shape=(64 , 64 , 1 )) x = layers.Conv2D(64 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(discriminator_input) x = layers.LeakyReLU(0.2 )(x) x = layers.Dropout(0.3 )(x) x = layers.Conv2D(128 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x) x = layers.BatchNormalization(momentum = 0.9 )(x) x = layers.LeakyReLU(0.2 )(x) x = layers.Dropout(0.3 )(x) x = layers.Conv2D(256 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x) x = layers.BatchNormalization(momentum = 0.9 )(x) x = layers.LeakyReLU(0.2 )(x) x = layers.Dropout(0.3 )(x) x = layers.Conv2D(512 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x) x = layers.BatchNormalization(momentum = 0.9 )(x) x = layers.LeakyReLU(0.2 )(x) x = layers.Dropout(0.3 )(x) x = layers.Conv2D( 1 , kernel_size=4 , strides=1 , padding="valid" , use_bias = False , activation = 'sigmoid' )(x) discriminator_output = layers.Flatten()(x) discriminator = models.Model(discriminator_input, discriminator_output)
值得一提的是,在这个模型中,卷积核尺寸为4。卷积之后的尺寸可以由:(图像尺寸-卷积核尺寸 + 2*填充值)/步长+1 计算。因此实际上,卷积核尺寸为4和尺寸为3对于尺寸的影响是一致的。因此,我们使用padding = 1即可。
将这些代码使用pyTorch重写,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Discriminator (nn.Module): def __init__ (self ): super (Discriminator,self).__init__() self.conv1 = nn.Conv2d(1 ,64 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.conv2 = nn.Conv2d(64 ,128 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.bn2 = nn.BatchNorm2d(128 ,momentum=0.9 ) self.conv3 = nn.Conv2d(128 ,256 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.bn3 = nn.BatchNorm2d(256 ,momentum=0.9 ) self.conv4 = nn.Conv2d(256 ,512 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.bn4 = nn.BatchNorm2d(512 ,momentum=0.9 ) self.conv5 = nn.Conv2d(512 ,1 ,kernel_size=4 ,stride=1 ,padding=0 ,bias=False ) def forward (self,x ): x = F.leaky_relu(self.conv1(x),0.2 ) x = F.dropout(x,0.3 ) x = F.leaky_relu(self.bn2(self.conv2(x)),0.2 ) x = F.dropout(x, 0.3 ) x = F.leaky_relu(self.bn3(self.conv3(x)), 0.2 ) x = F.dropout(x, 0.3 ) x = F.leaky_relu(self.bn4(self.conv4(x)), 0.2 ) x = F.dropout(x, 0.3 ) x = torch.sigmoid(self.conv5(x)) return x.flatten()
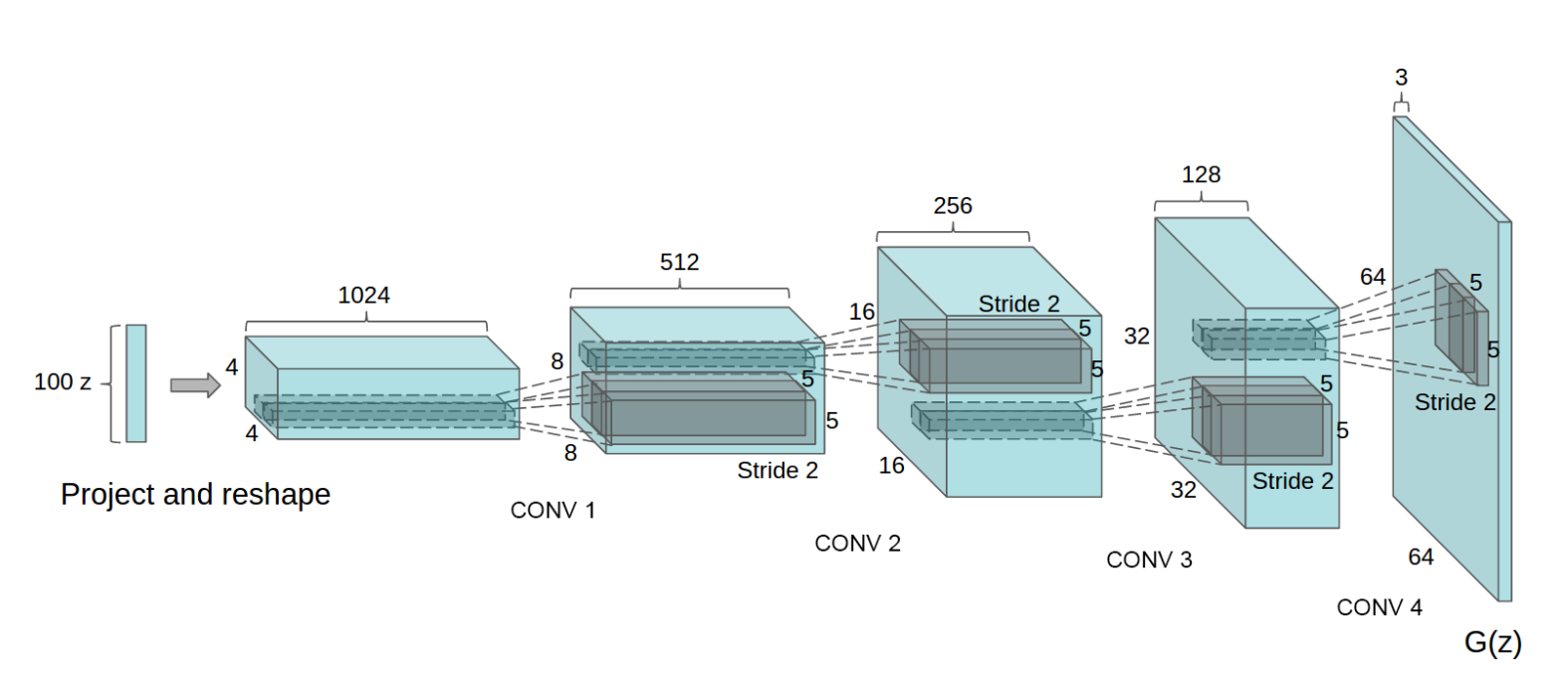
生成器 使用Tensorflow实现的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 generator_input = layers.Input(shape=(100 ,)) x = layers.Reshape((1 , 1 , 100 ))(generator_input) x = layers.Conv2DTranspose(512 , kernel_size=4 , strides=1 , padding="valid" , use_bias = False )(x) x = layers.BatchNormalization(momentum=0.9 )(x) x = layers.LeakyReLU(0.2 )(x) x = layers.Conv2DTranspose(256 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x) x = layers.BatchNormalization(momentum=0.9 )(x) x = layers.LeakyReLU(0.2 )(x) x = layers.Conv2DTranspose(128 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x) x = layers.BatchNormalization(momentum=0.9 )(x) x = layers.LeakyReLU(0.2 )(x) x = layers.Conv2DTranspose(64 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x) x = layers.BatchNormalization(momentum=0.9 )(x) x = layers.LeakyReLU(0.2 )(x) generator_output = layers.Conv2DTranspose( 1 , kernel_size=4 , strides=2 , padding="same" , use_bias = False , activation = 'tanh' )(x) generator = models.Model(generator_input, generator_output)
值得注意的有这几点:
输入是一个100维的随机向量
在训练过程中,空间形状逐渐增加,通道数逐渐减少
最后使用tanh函数将输出转化为[-1,1]的范围
使用pyTorch的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Generator (nn.Module): def __init__ (self ): super (Generator,self).__init__() self.convt1 = nn.ConvTranspose2d(100 ,512 ,kernel_size=4 ,stride=1 ,padding=0 ,bias=False ) self.bn1 = nn.BatchNorm2d(512 ,momentum=0.9 ) self.convt2 = nn.ConvTranspose2d(512 ,256 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.bn2 = nn.BatchNorm2d(256 ,momentum=0.9 ) self.convt3 = nn.ConvTranspose2d(256 ,128 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.bn3 = nn.BatchNorm2d(128 ,momentum=0.9 ) self.convt4 = nn.ConvTranspose2d(128 ,64 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) self.bn4 = nn.BatchNorm2d(64 ,momentum=0.9 ) self.convt5 = nn.ConvTranspose2d(64 ,1 ,kernel_size=4 ,stride=2 ,padding=1 ,bias=False ) def forward (self,x ): x = x.view(-1 ,100 ,1 ,1 ) x = F.relu(self.bn1(self.convt1(x))) x = F.relu(self.bn2(self.convt2(x))) x = F.relu(self.bn3(self.convt3(x))) x = F.relu(self.bn4(self.convt4(x))) x = torch.tanh(self.convt5(x)) return x
并无特别需要注意的部分。
一种使用上采样替换转置 1 x = layers.Conv2DTranspose(256 , kernel_size=4 , strides=2 , padding="same" , use_bias = False )(x)
与
1 2 x = layers.UpSampling2D(size = 2 )(x) x = layers.Conv2D(256 , kernel_size=4 , strides=1 , padding="same" )(x)
有类似的效果
模型训练 训练原理
鉴别器 我们可以通过创建一个训练集来训练鉴别器,其中一些图像是来自训练集的真实观察结果,一些是来自生成器的假输出。然后我们将其视为监督学习问题,其中真实图像的标签为 1,假图像的标签为 0,并以二元交叉熵作为损失函数 。
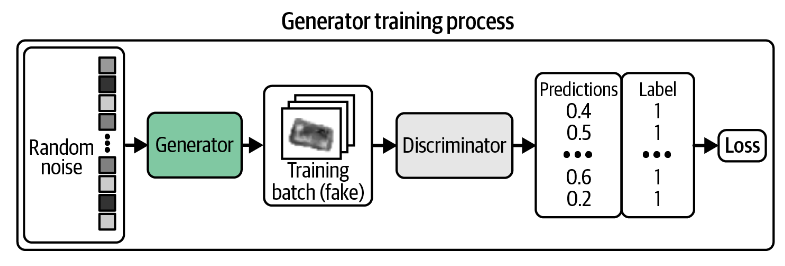
生成器 我们需要找到一种对每个生成的图像进行评分的方法,以便它可以针对高分图像进行优化。幸运的是,我们有一个鉴别器可以做到这一点!我们可以生成一批图像并将它们传递给鉴别器以获得每个图像的分数。生成器的损失函数就是这些概率和一个由1组成的向量的二元交叉熵。
交替训练 我们必须交替训练这两个网络,确保一次只更新一个网络的权重。
DCGAN类 ** **
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class DCGAN (models.Model): def __init__ (self, discriminator, generator, latent_dim ): super (DCGAN, self).__init__() self.discriminator = discriminator self.generator = generator self.latent_dim = latent_dim def compile (self, d_optimizer, g_optimizer ): super (DCGAN, self).compile () self.loss_fn = losses.BinaryCrossentropy() self.d_optimizer = d_optimizer self.g_optimizer = g_optimizer self.d_loss_metric = metrics.Mean(name="d_loss" ) self.g_loss_metric = metrics.Mean(name="g_loss" ) @property def metrics (self ): return [self.d_loss_metric, self.g_loss_metric] def train_step (self, real_images ): batch_size = tf.shape(real_images)[0 ] random_latent_vectors = tf.random.normal( shape=(batch_size, self.latent_dim) ) with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: generated_images = self.generator( random_latent_vectors, training = True ) **real_predictions = self.discriminator(real_images, training = True )** **fake_predictions = self.discriminator( generated_images, training = True )** real_labels = tf.ones_like(real_predictions) real_noisy_labels = real_labels + 0.1 * tf.random.uniform( tf.shape(real_predictions) ) fake_labels = tf.zeros_like(fake_predictions) fake_noisy_labels = fake_labels - 0.1 * tf.random.uniform( tf.shape(fake_predictions) ) d_real_loss = self.loss_fn(real_noisy_labels, real_predictions) d_fake_loss = self.loss_fn(fake_noisy_labels, fake_predictions) d_loss = (d_real_loss + d_fake_loss) / 2.0 g_loss = self.loss_fn(real_labels, fake_predictions) gradients_of_discriminator = disc_tape.gradient( d_loss, self.discriminator.trainable_variables ) gradients_of_generator = gen_tape.gradient( g_loss, self.generator.trainable_variables ) self.d_optimizer.apply_gradients( zip (gradients_of_discriminator, discriminator.trainable_variables) ) self.g_optimizer.apply_gradients( zip (gradients_of_generator, generator.trainable_variables) ) self.d_loss_metric.update_state(d_loss) self.g_loss_metric.update_state(g_loss) return {m.name: m.result() for m in self.metrics}
complie中的损失函数
self.d_loss_metric = metrics.Mean(name="d_loss")创建了一个名为”d_loss”的度量对象,用于计算判别器的平均损失。self.g_loss_metric = metrics.Mean(name="g_loss")创建了一个名为”g_loss”的度量对象,用于计算生成器的平均损失。在每个训练步骤中,可以使用self.d_loss_metric.update_state(loss)和self.g_loss_metric.update_state(loss)来更新这两个度量的状态,其中loss是在当前步骤中计算得到的损失。
可以使用self.d_loss_metric.result()和self.g_loss_metric.result()来获取当前的平均损失。
train_step的修改
batch_size = tf.shape(real_images)[0]:获取输入的真实图像的批次大小。random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim)):生成一批随机的潜在向量,这些向量将被用作生成器的输入。with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape::创建两个tf.GradientTape上下文,用于自动计算生成器和判别器的梯度。
在tf.GradientTape的上下文中,首先使用生成器生成一批假的图像,然后使用判别器对真实的图像和假的图像进行预测。然后,计算判别器对真实图像和假图像预测的损失。
real_noisy_labels和real_labels的主要区别在于real_noisy_labels添加了一些随机噪声。这是一种常见的训练生成对抗网络(GAN)的技巧,被称为标签平滑(label smoothing)。标签平滑的目的是防止模型过于自信。
计算判别器和生成器的梯度。
使用优化器更新判别器和生成器的权重。
更新判别器和生成器的损失度量。
返回所有度量的当前值。
** **
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class DCGAN (nn.Module): def __init__ (self, discriminator, generator, latent_dim ): super (DCGAN, self).__init__() self.discriminator = discriminator self.generator = generator self.latent_dim = latent_dim def forward (self, real_images ): batch_size = real_images.shape[0 ] random_latent_vectors = torch.randn((1 ,batch_size, self.latent_dim)).cuda() generated_images = self.generator(random_latent_vectors) real_predictions = self.discriminator(real_images) fake_predictions = self.discriminator(generated_images) return real_predictions, fake_predictions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def train (dcgan, data_loader, d_optimizer, g_optimizer, loss_fn, epochs ): generated_images = [] for epoch in range (epochs): for i, (real_images, _) in enumerate (data_loader): d_optimizer.zero_grad() real_images = real_images.cuda() real_predictions, fake_predictions = dcgan(real_images) real_labels = torch.ones_like(real_predictions) real_noisy_lables = real_labels - 0.1 * torch.rand_like(real_predictions) fake_labels = torch.zeros_like(fake_predictions) fake_noisy_labels = fake_labels + 0.1 * torch.rand_like(fake_predictions) d_loss_real = loss_fn(real_predictions, real_noisy_lables) d_loss_fake = loss_fn(fake_predictions, fake_noisy_labels) d_loss = (d_loss_real + d_loss_fake) / 2 d_loss.backward() d_optimizer.step() g_optimizer.zero_grad() g_real_predictions, g_fake_predictions = dcgan(real_images) g_loss = loss_fn(g_fake_predictions, real_labels) g_loss.backward() g_optimizer.step() if i % 50 == 0 : print (f"Epoch {epoch} , Batch {i} , D loss: {d_loss.item()} , G loss: {g_loss.item()} " )
需要注意的几点是:
在使用PyTorch的版本中,调用了两次dcgan得到正确和错误的预测,这是参照PyTorch官网的教程设置的。如果不调用两次,在d_loss.backward中设置保留梯度信息可能也是一种解决方案。
DCGAN Tutorial — PyTorch Tutorials 2.2.0+cu121 documentation
损失函数被设置成从外部输入,在这里我们应该使用二元交叉熵函数nn.BCEloss() ,在实际应用中,如果使用了nn.BCEWithLogitsLoss() 会导致梯度不能下降。而这里有一些讨论:
在tensorflow的设置中,标签平滑被设置为
1 2 real_noisy_labels = real_labels + 0.1 * tf.random.uniform(tf.shape(real_predictions)) fake_noisy_labels = fake_labels - 0.1 * tf.random.uniform(tf.shape(fake_predictions))
这使得真实图片的标签大于1,而虚假图片的标签小于1,我并不清楚作者这样设置的目的,但这在PyTorch中会引发错误。
因此我们将其设置为:
1 2 real_noisy_lables = real_labels - 0.1 * torch.rand_like(real_predictions) fake_noisy_labels = fake_labels + 0.1 * torch.rand_like(fake_predictions)
nn.BCEWithLogitsLoss() 被定义为:
会引入额外的sigmoid函数,而我们在判别器中已经设置了sigmoid函数,这会导致loss函数受到额外的处理。
训练结果分析 训练之后的模型预测结果如下
** **
使用PyTorch的预测结果
GAN训练:技巧和窍门 鉴别器和生成器:一方的优势 当鉴别器或生成器一方占据极大优势,会导致梯度完全消失,训练无法进行下去。
在这种情况下,我们要降低一方的优势
** **
增加鉴别器中的Dropout层的速率参数,以减少流经网络的信息量。
降低鉴别器的学习率。
减少鉴别器中的卷积层的数量。
在训练鉴别器时为标签添加噪声。
在训练鉴别器时随机翻转一些图像的标签。
** **
降低两个网络的学习率并增加批量大小
反转上述所有操作
损失函数和图像质量的不一致性 生成器仅根据当前鉴别器进行分级,并且鉴别器不断改进,因此我们无法比较训练过程中不同点评估的损失函数。有时,生成器的损失函数实际上随着时间的推移而增加,尽管图像的质量明显提高。生成器损失和图像质量之间缺乏相关性有时会使GAN训练难以监控 。
超参数 所看到的,即使使用简单的GANs,也有大量的超参数需要调整。除了鉴别器和生成器的整体架构外,还有控制批量归一化、丢弃、学习率、激活层、卷积滤波器、内核大小、跨步、批量大小和潜在空间大小的参数需要考虑。GANs对所有这些参数的微小变化都非常敏感,找到一组有效的参数通常是经过大量的试错,而不是遵循一套既定的指导方针。
Wasserstein GAN with Gradient Penalty (WGAN-GP)
WGAN是2017年引入的一种针对GAN的优化。其最重要的贡献是引入了Wasserstein损失函数,使得损失函数与图片质量的相关性增加,提高了训练的稳定性。
Wasserstein 损失函数 损失函数的定义 首先回顾二元交叉熵损失函数:
对于GAN的鉴别器,其训练的目标:
对于GAN的生成器,其训练的目标:
现在我们来讨论Wasserstein损失函数
首先,我们使用1和-1作为标签,而不是0,1
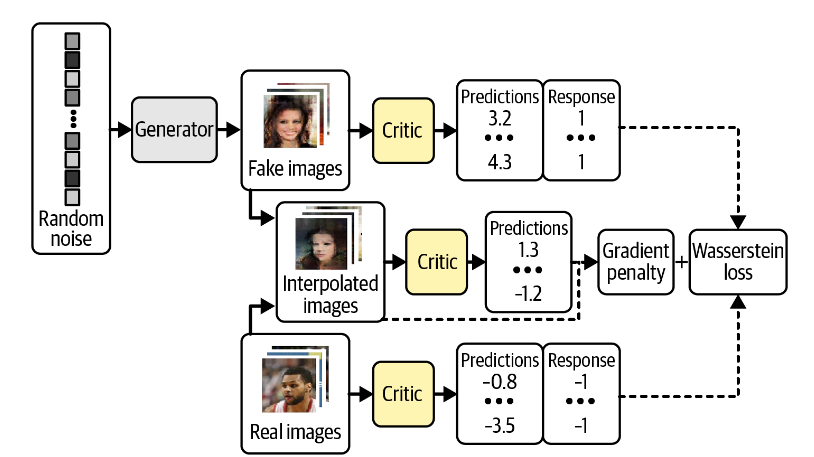
我们移除鉴别器最后的sigmoid层,由此预测的值没有限制在$[0,1]$,而是在$(-\infty, \infty)$。由此,我们一般称WGAN中的鉴别器discriminator为评价器critic,因为它给出了得分score,而不是一个概率。
Wasserstein损失函数被定义为:
然后我们设置真实的图像的标签为1,虚假的图像的标签为-1,以此设置评价器的训练目标:
即批评者试图最大化其对真实图像和生成图像的预测之间的差异。
而对于生成器,其训练的目标为:
利普西茨约束 回想我们删除了评价器sigmoid层,这会导致我们可能得到一个相当不稳定的损失函数,这并不是我们通常来说希望的。因此我们还需要加入1-Lipschitz连续的约束条件
所谓对评价器加入1-Lipschitz约束条件,即引入:
的条件。其中,$\left|x_1-x_2\right|$是两个图像之间的平均像素绝对差。
引入梯度gradient penalty 乘法项 原作者使用梯度裁剪weight clipping的方式保证利普西茨约束的存在,而后世的研究者使用了更好的方法。即在损失函数中引入梯度惩罚gradient penalty。
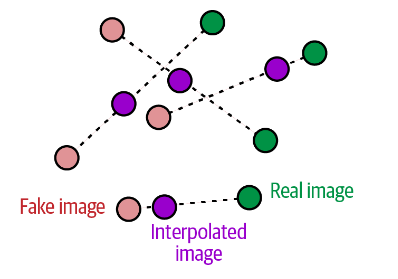
梯度惩罚损失测量输入图像的预测的梯度的范数 与1之间的平方差。但计算所有位置的梯度是不切实际的,WGAN-GP只计算之随机的选择真图像和假图像的插值点。
gradient penalty 的算法 使用tensorflow的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def gradient_penalty (self, batch_size, real_images, fake_images ): alpha = tf.random.normal([batch_size, 1 , 1 , 1 ], 0.0 , 1.0 ) diff = fake_images - real_images interpolated = real_images + alpha * diff with tf.GradientTape() as gp_tape: gp_tape.watch(interpolated) pred = self.critic(interpolated, training=True ) grads = gp_tape.gradient(pred, [interpolated])[0 ] norm = tf.sqrt(tf.reduce_sum(tf.square(grads), axis=[1 , 2 , 3 ])) gp = tf.reduce_mean((norm - 1.0 ) ** 2 ) return gp
使用PyTorch的复现十分简单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def gradient_penalty (self, batch_size, real_images, fake_images ): alpha = torch.rabd((batch_size,1 ,1 ,1 )).to(self.device) diff = fake_images-real_images interpolated = real_images + alpha*diff interpolated.requires_grad_(True ) pred = self.critic(interpolated) grads = torch.autograd.grad( outputs=pred, inputs=interpolated, grad_outputs=torch.ones_like(pred), create_graph=True , retain_graph=True , )[0 ] norm = grads.view(grads.size(0 ),-1 ).norm(2 ,dim = 1 ) gp = ((norm-1.0 ) ** 2 ).mean() return gp
两行代码唯一稍有区别的地方是两个库的梯度计算函数。
训练WGAN-GP模型 在使用Wasserstein损失函数之后,我们不再需要担心评价者和生成者训练的平衡。现在,在更新生成器之前,必须对评价者进行收敛训练,以确保生成器更新的梯度是准确的。因此,我们会在生成器更新之前多次(3-5次)训练评价者。
修改DCGAN的train_step函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def train_step (self, real_images ): batch_size = tf.shape(real_images)[0 ] for i in range (self.critic_steps): random_latent_vectors = tf.random.normal( shape=(batch_size, self.latent_dim) ) with tf.GradientTape() as tape: fake_images = self.generator( random_latent_vectors, training=True ) fake_predictions = self.critic(fake_images, training=True ) real_predictions = self.critic(real_images, training=True ) c_wass_loss = tf.reduce_mean(fake_predictions) - tf.reduce_mean( real_predictions ) c_gp = self.gradient_penalty( batch_size, real_images, fake_images ) c_loss = c_wass_loss + c_gp * self.gp_weight c_gradient = tape.gradient(c_loss, self.critic.trainable_variables) self.c_optimizer.apply_gradients( zip (c_gradient, self.critic.trainable_variables) ) random_latent_vectors = tf.random.normal( shape=(batch_size, self.latent_dim) ) with tf.GradientTape() as tape: fake_images = self.generator(random_latent_vectors, training=True ) fake_predictions = self.critic(fake_images, training=True ) g_loss = -tf.reduce_mean(fake_predictions) gen_gradient = tape.gradient(g_loss, self.generator.trainable_variables) self.g_optimizer.apply_gradients( zip (gen_gradient, self.generator.trainable_variables) ) self.c_loss_metric.update_state(c_loss) self.c_wass_loss_metric.update_state(c_wass_loss) self.c_gp_metric.update_state(c_gp) self.g_loss_metric.update_state(g_loss) return {m.name: m.result() for m in self.metrics}
将这些代码使用PyTorch复现。
首先修改WGAN类,唯一的区别是除了原本返回的real_prediction和fake_predictions之外,还要返回generated_images,用来计算梯度损失。另外,上文提到的引入的梯度损失函数无论是作为一个单独的函数还是放在WGAN类中都可以。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class WGAN (nn.Module): def __init__ (self, critic, generator, latent_dim ): super (WGAN, self).__init__() self.critic = critic self.generator = generator self.latent_dim = latent_dim self.c_optimizer = torch.optim.Adam(self.critic.parameters()) self.g_optimizer = torch.optim.Adam(self.generator.parameters()) def forward (self, real_images ): batch_size = real_images.shape[0 ] random_latent_vectors = torch.randn((1 ,batch_size, self.latent_dim)).cuda() generated_images = self.generator(random_latent_vectors) real_predictions = self.critic(real_images) fake_predictions = self.critic(generated_images) return real_predictions, fake_predictions, generated_images def gradient_penalty (self, batch_size, real_images, fake_images ): ... return gp
然后修改训练代码,主要的区别在于损失函数的计算。仿照tensorflow的实现修改损失函数的计算方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def train (wgan, data_loader, c_optimizer, g_optimizer, epochs ): generated_images = [] for epoch in range (epochs): for i, (real_images, _) in enumerate (data_loader): real_images = real_images.cuda() batch_size = real_images.shape[0 ] for i in range (CRITIC_STEPS): real_predictions,fake_predictions,fake_images = wgan(real_images) c_wass_loss = fake_predictions.mean() - real_predictions.mean() c_gp = wgan.gradient_penalty(batch_size, real_images, fake_images) c_loss = c_wass_loss + c_gp * GP_WEIGHT c_optimizer.zero_grad() c_loss.backward() c_optimizer.step() real_predictions,fake_predictions,fake_images = wgan(real_images) g_loss = -fake_predictions.mean() g_optimizer.zero_grad() g_loss.backward() g_optimizer.step()
结果分析 乐高积木数据集上的结果分析 Tensorflow实现的结果 Tensorflow的训练代码的代数设置很奇怪,以下是按照程序设置的200代得到的结果,但效果好像有限,这可能跟代数的错误理解有关。
PyTorch实现的结果 以下是PyTorch在25代得出的结果。看起来与DCGAN的区别不大
CelebA数据集上的结果分析 Tensorflow实现的结果 因为与之前描述的相同问题,我不能正确的设置代数。这是按照程序中设置epoch = 600的结果。但训练速度并不像训练600应有的速度。
感觉上效果好像并不如VAE。这可能是部分参数的调节有问题,或者单纯的风格问题。VAE倾向于生成模糊颜色边界的较软图像,而GANs则会生成更清晰、定义更明确的图像。也可能是训练代数不够的问题,一般来说,GAN通常比VAE更难训练,并且需要更长的时间才能达到令人满意的质量。
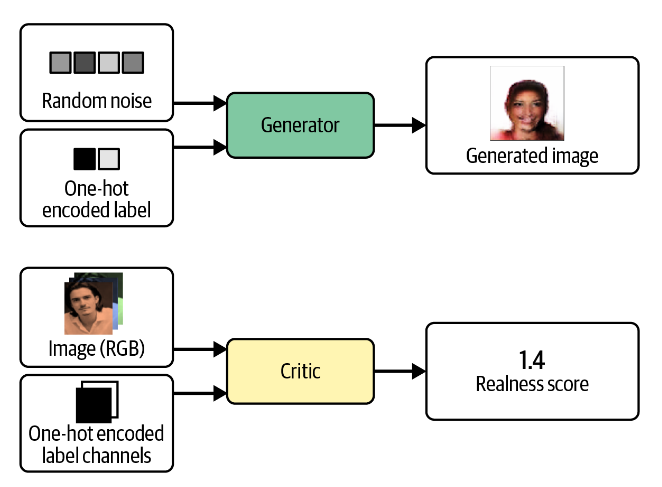
Conditional GAN (CGAN) CGAN是对GAN的简单扩展,使得我们能够指定生成的图像类型。由于之前的程序中可能存在一些问题,所以结合之前的程序,重新设计了CGAN的程序,被储存在chapter_4/CGAN/cgan_pytorch.ipynb ,相比于前两个PyTorch程序,这个程序可能有更少的错误。
CGAN的结构
相比于GAN,CGAN只是简单的将标签的One-hot变化作为输入输入到生成器和评价中。
解析Tensorflow代码,并使用PyTorch复现 加载标签,读入数据 list_attr_celeba.csv是一个存放一些样貌标签的文件,对于每张图片,使用-1标记其不属于的标签,使用1标记其属于的文件。其标签包括
1 5_o_Clock_Shadow,Arched_Eyebrows,Attractive,Bags_Under_Eyes,Bald,Bangs,Big_Lips,Big_Nose,Black_Hair,Blond_Hair,Blurry,Brown_Hair,Bushy_Eyebrows,Chubby,Double_Chin,Eyeglasses,Goatee,Gray_Hair,Heavy_Makeup,High_Cheekbones,Male,Mouth_Slightly_Open,Mustache,Narrow_Eyes,No_Beard,Oval_Face,Pale_Skin,Pointy_Nose,Receding_Hairline,Rosy_Cheeks,Sideburns,Smiling,Straight_Hair,Wavy_Hair,Wearing_Earrings,Wearing_Hat,Wearing_Lipstick,Wearing_Necklace,Wearing_Necktie,Young
我们这里只关注LABEL = "Blond_Hair” 的图像。
为了在PyTorch中重现这原书使用tensorflow的实现方法,我们需要定义一个继承自Dataset的数据库类。一般的,我们只需要改变其__init__ ,__len__,__getitem__ 三个函数即可。其中,第三个函数要定义我们加载某一个数据的数据和标签的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class BHDataset (Dataset ): def __init__ (self, img_dir, label, transform=None ): self.img_dir = img_dir self.transform = transform self.attributes = pd.read_csv(LABEL_DIR) self.labels = self.attributes[label] self.int_labels = np.where(self.labels == 1 , self.labels, 0 ) self.img_names = os.listdir(img_dir) def __len__ (self ): return len (self.img_names) def __getitem__ (self, idx ): img_path = os.path.join(self.img_dir, self.img_names[idx]) image = Image.open (img_path).convert('RGB' ) label = torch.tensor(self.int_labels[idx]).cuda() if self.transform: image = self.transform(image).cuda() return image, label preprocess = transforms.Compose([ transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), transforms.ToTensor(), transforms.Lambda(lambda x: (x * 255.0 - 127.5 ) / 127.5 ), ]) train_data = BHDataset(img_dir=IMG_DIR, label=LABEL, transform=preprocess) train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True , num_workers=0 )
在这里我们使用相同的方法读取标签数据,并使用PIL库来读取图片。由此,我们也解决了一直以来使用PyTorch的读取文件的方式的标签和文件夹相关的问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 data_iter = iter (train_loader) images, labels = next (data_iter) real_batch_images = images[0 :10 ] real_batch_label = labels[0 :10 ] real_batch_images = np.transpose(torch.squeeze(real_batch_images).cpu().numpy(),(0 ,2 ,3 ,1 )) display(real_batch_images, cmap="gray_r" , as_type="float32" ) blond_hair_images = images[labels == 1 ] blond_hair_images = np.transpose(torch.squeeze(blond_hair_images[0 :10 ]).cpu().numpy(),(0 ,2 ,3 ,1 )) display(blond_hair_images, cmap="gray_r" , as_type="float32" )
使用display函数展示一些数据,验证是否正确加载。之前应该没有描述过display函数,这是原书代码中的一个工具函数。其具体实现为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def display ( images, n=10 , size=(20 , 3 "gray_r" , as_type="float32" , save_to=None """ Displays n random images from each one of the supplied arrays. """ if images.max () > 1.0 : images = images / 255.0 elif images.min () < 0.0 : images = (images + 1.0 ) / 2.0 plt.figure(figsize=size) for i in range (n): _ = plt.subplot(1 , n, i + 1 ) plt.imshow(images[i].astype(as_type), cmap=cmap) plt.axis("off" ) if save_to: plt.savefig(save_to) print (f"\nSaved to {save_to} " ) plt.show()
展示一些图片,其中第一行随机选择,有金发也有非金发;第二行则全部为金发。比较两行,发现第一行中所有金发人像都在第二行中,且第二行中不包括非金发人像。证明图片加载正确。
模型 评价器和生成器的模型与之前基本一致,参见chapter_4/CGAN/cgan_pytorch.ipynb 中相应代码即可。相比于之前的WGAN和DCGAN将模型类和训练函数分开的版本,在这次实现中我将他们集成在同一个类中。大致结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class ConditionalWGAN (nn.Module): def __init__ (self,critic,generator,latent_dim,critic_step,gp_weight ): '''初始化模型''' ... def forward (self,real_images,labels ): '''前向传播''' ... def gradient_penalty (self, real_images, generated_images, labels ): '''计算梯度惩罚''' ... def train_model (self,data_loader,epochs ): '''训练模型''' ... def test_model (self,labels = 0 ): '''测试模型''' ... def save (self, filepath = 'model/conditional_wgan.pth' ): '''保存模型''' ... def load (self, filepath= 'model/conditional_wgan.pth' ): '''加载模型''' ...
如此我们可以调用相应的功能进行模型的训练,测试等功能。
结果分析
这是使用模型生成的金发图像。可见迭代25代的效果还是有限。