
Chapter 10 Advanced GANs 各种各样的GAN
Chapter 10 Advanced GANs 各种各样的GAN
在本次学习的最后,回归最初学习的目的,来尝试了解各种各样的GAN网络。我可能会尝试实现其中的一些模型。

- 三个的建立在早期论文思想上的重要模型
ProGAN → StyleGAN → StyleGAN2- 了解
ProGAN模型。 - 理解
ProGAN如何被改造以构建StyleGAN - 探索
StyleGAN如何被调整以创建StyleGAN2 - 了解这些模型的关键贡献,包括渐进式训练、自适应实例归一化、权重调制和解调以及路径长度正则化。’
- 了解
- 两个引入了注意力机制的模型
SAGAN → BigGAN- 了解
Self-Attention GAN (SAGAN)的架构,该架构将注意力机制纳入GAN框架。 - 了解
BigGAN如何扩展SAGAN论文中的想法以产生高质量的图像。
- 了解
- 两个融合了VAE,Transformers和GAN思想的模型
VQ-GAN → ViT VQ-GAN- 了解
VQ-GAN如何使用码本将图像编码为可以使用Transformer建模的离散序列的token。 - 了解
ViT VQ-GAN如何调整VQ-GAN架构以在编码器和解码器中使用Transformers而不是卷积层。
- 了解
ProGAN
ProGAN旨在提高GAN的训练速度和稳定性。它引入了渐进训练机制。
ProGAN: Progressive Growing Generative Adversarial Networks
Progressive
渐进训练主张首先训练一个轻量级的GAN来使出准确的低分辨率图像,然后逐步提高分辨率。

网络结构
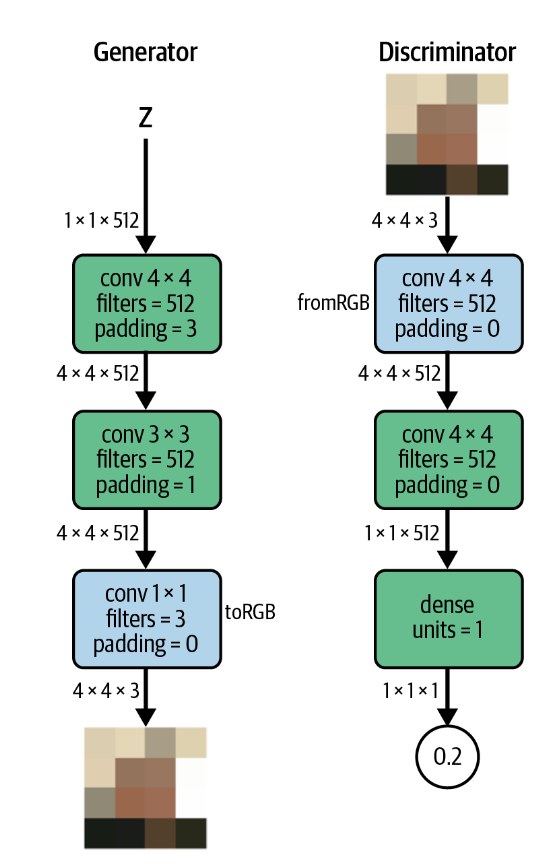
首先我们构建一个能够生成\(4\times4\times3\)的图像的模型。其中蓝色块表示特征图和RGB的相互转变的卷积层。而且在这一步中,上采样并不是通过转置卷积实现,而是使用padding将一个\(1\times1\times512\)的图像直接补充到\(4\times4\times512\),再经过一个卷积层来实现。
接下来,我们关注现在训练的模型如何应用于更高分辨率的图像。
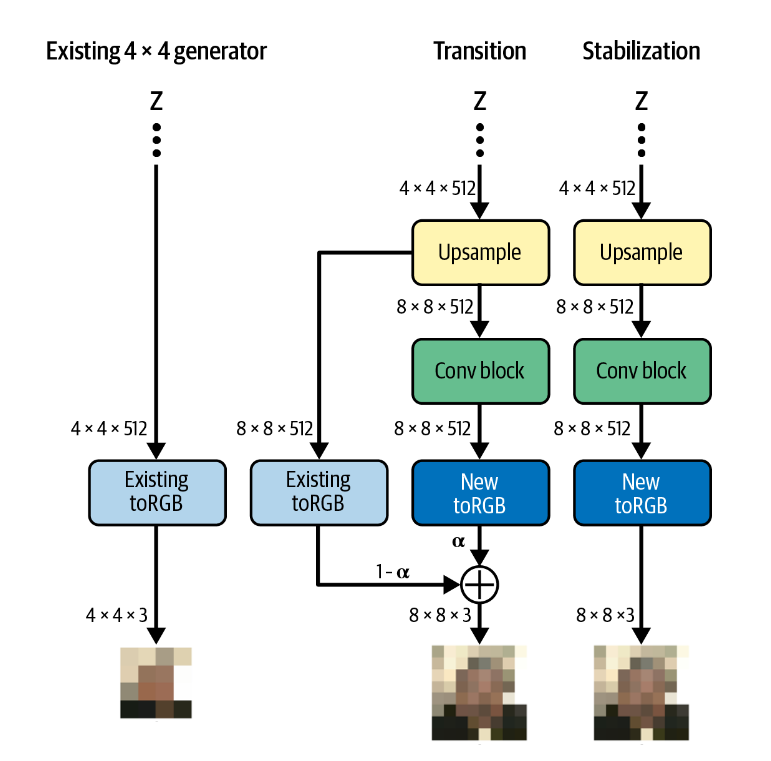
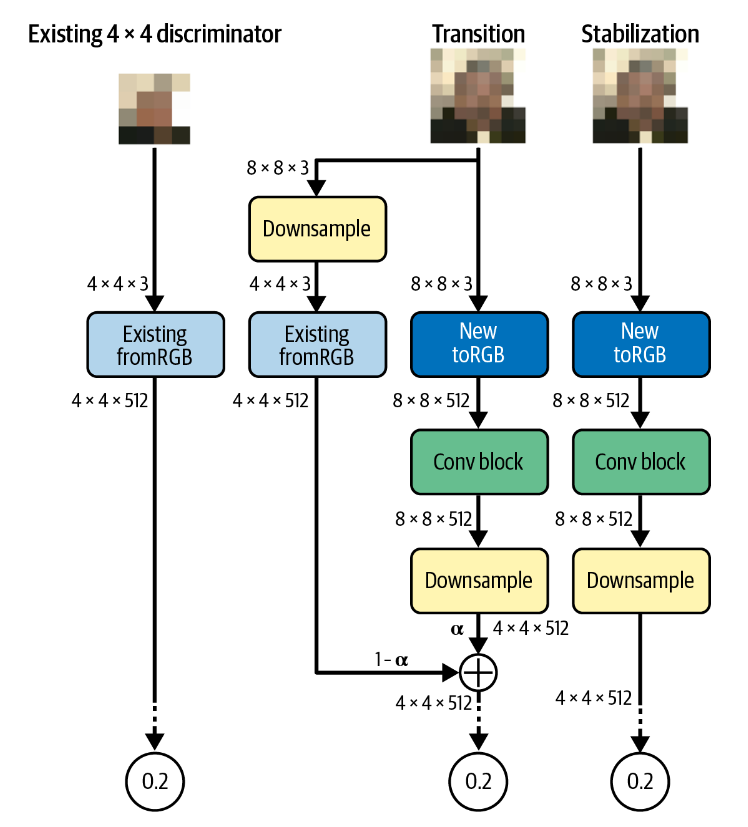
生成器和判别器的训练方式相似。
- 对于生成器,图像经过与之前步骤相同的处理转化为\(4\times4\times512\)的特征,然后经过上采样得到\(8\times8\times512\)的新特征。特征会分别经过
旧toRGB块和新toRGB块生成新图像,并通过权重\(\alpha\)加权得到最终的图像。再训练过程中,\(\alpha\)逐渐增大,直到完全不经过旧toRGB块。 - 对于判别器,图像同时被下采样后经过
旧fromRGB块和经过新fromRGB块后进行处理,两条路径的结果经过\(\alpha\)的权重加权平均得到一个\(4\times4\times512\)的向量,并经过相同的处理得到预测结果。\(\alpha\)不断增大,直到完全不经过旧fromRGB块。
再提升到\(8\times8\)的分辨率后,我们在原本的生成器上增加一个上采样层,一个卷积层和一个toRGB块。在原本的判别器上增加了一个fromRGB块,一个卷积层和一个下采样。在训练过程中,每次我们提升分辨率都会增加这些层。我们的训练过程可以表示为:
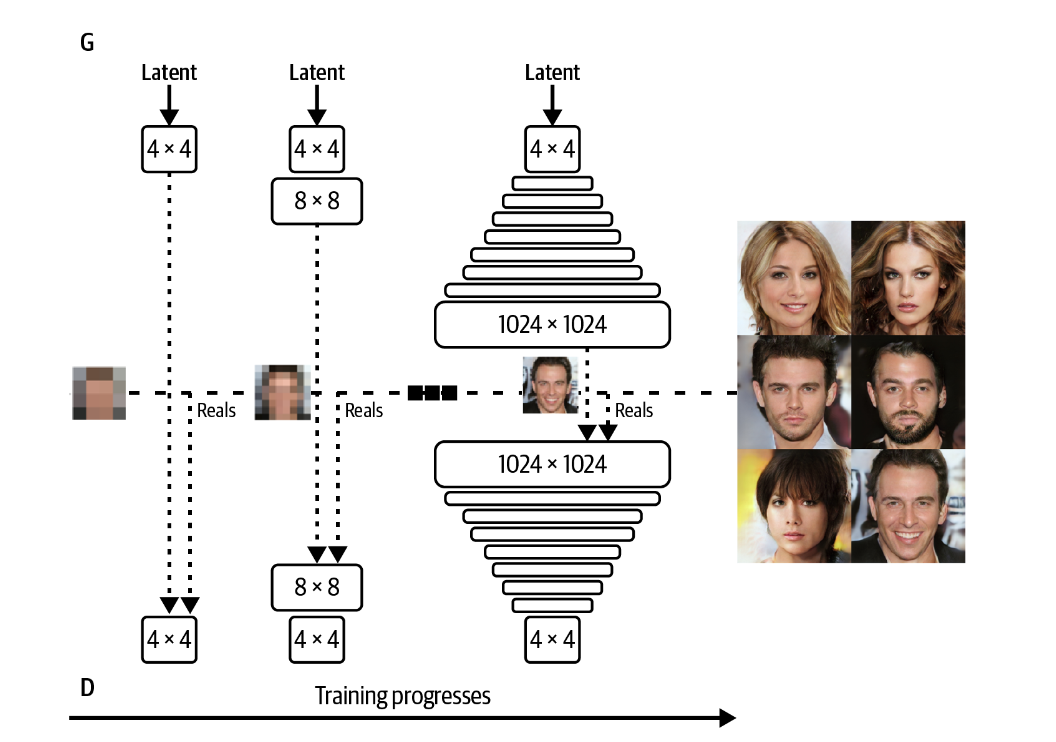
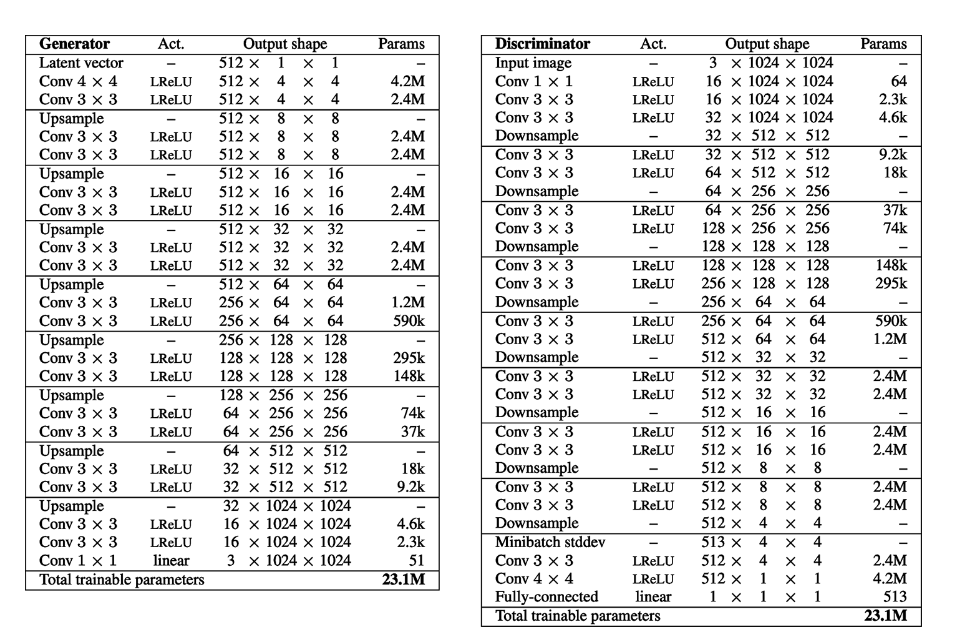
注意所有的层都是可以训练的,没有任何层被锁死。
一些其他细节
小批次标准偏差 Minibatch standard deviation
小批次标准偏差层是鉴别器中的一个额外层,它附加特征值的标准偏差,在所有像素和微批次上进行平均,作为附加(恒定)特征。
这有利于生成器在输出中创造更多的多样性。
均衡学习率 Equalized learning rates
ProGAN中的所有全连接层和卷积层都使用均衡的学习率。
通常,神经网络中的权重是使用He初始化等方法初始化的,He初始化是一种高斯分布,其中标准偏差被缩放为与层输入数量的平方根成反比。这样,具有更多输入数量的层将被初始化为具有与零的较小偏差的权重,这通常提高了训练过程的稳定性。
ProGAN的研究发现在使用Adam或RMSProp这些优化器时,这回造成问题。会导致时间花费更长,且两个模型的训练速度不平衡。
通过均衡的学习率,我们可以相应地缩放每一层的权重。该公式类似于He初始化。但是,均衡学习率并没有将其用作单个初始化器,而是在每个前向传递中使用它。
逐像素归一化 Pixelwise normalization
最后,在ProGAN中,生成器中使用逐像素归一化,而不是批量归一化。逐像素归一化层没有可训练的权重。
StyleGAN
在训练GANs时,很难在潜在空间中分离出与高级属性相对应的向量,它们经常纠缠在一起,比如我们生成的图像面部出现更多雀斑,或者背景的颜色出现在面部等等。StyleGAN旨在完全控制图像的风格,即准确的分离潜在空间的特征。
结构
StyleGAN通过在不同的位置将样式向量style vector显式地注入网络来实现这一点,下图是StyleGAN的整体结构。
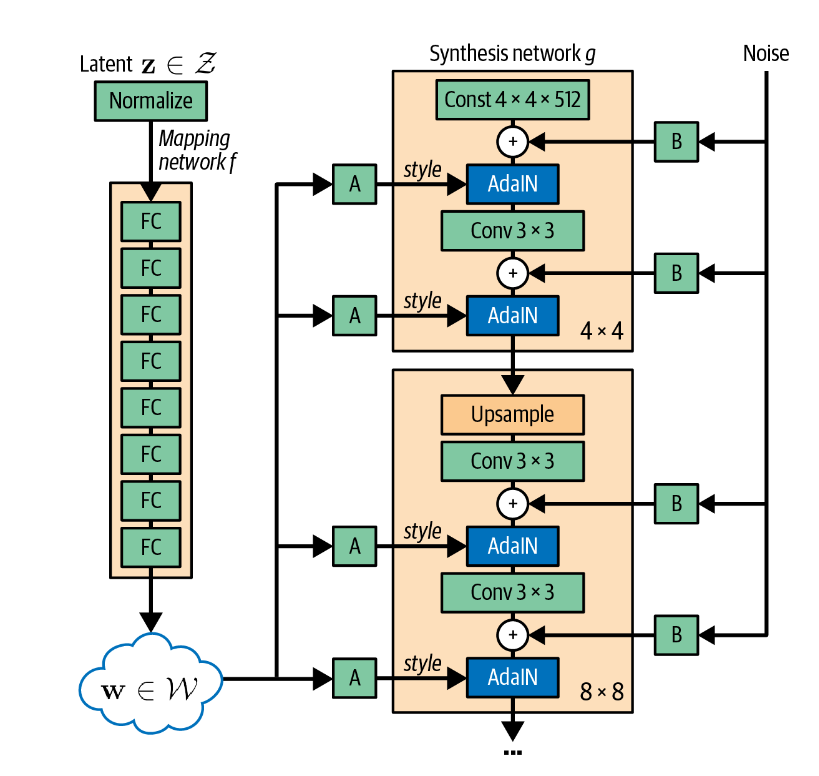
Mapping Network
Mapping Network是一系列向前传播的神经网络,将噪音输入映射到不同的潜在空间\(\mathcal{W}\),为输入向量被分解提供可能。这样做使得选择图像风格的过程(Mapping Network)和生成给定风格的图像的过程(Synthesis Network)分离。
Synthesis Network
Synthesis Network根据Mapping Network提供的风格,生成具有这些风格的图像。风格向量\(\mathbf{w}\)在不同的点被注入到合成网络中。向量通过不同的全连接层\(\mathbf{A}_i\),给出两个向量:缩放向量\(y_{s,i}\)和平移向量\(y_{b,i}\)。这些向量告诉网络如何调整特征图。这些调整通过AdalN层实现。
AdalN层
AdalN层adaptive instance normalization
layers使用风格的两个向量调整特征图x_i的均值和方差。这一层不改变特征图尺寸。
\[ \operatorname{AdaIN}\left(\mathbf{x}_i, \mathbf{y}\right)=\mathbf{y}_{s, i} \frac{\mathbf{x}_i-\mu\left(\mathbf{x}_i\right)}{\sigma\left(\mathbf{x}_i\right)}+\mathbf{y}_{b, i} \]
AdaIN层保证在图像被加工的每一步都能接收到完整的风格信息,从而避免在传递过程中风格信息的丢失。这可以使得潜在向量中的特征更容易分离。
风格混合 Style Mixing
作者使用了一种称为样式混合的技巧来确保生成器在训练期间不能利用相邻样式之间的相关性。在实践中,并非只采样了一个潜在向量\(\mathbf{z}\),而是同时采样了两个潜在向量\(\left(\mathbf{z}_1, \mathbf{z}_2\right)\),并得到了两个风格\(\left(w_1, w_2\right)\)向量。在每一层,这两个向量被随机选择,从而打破向量之间任何可能的相关性。
随机变化 Stochastic variation
生成器在每次卷积之后都会增加噪音,以充分考虑局部的细节。
StyleGAN2
这一系列重要的 GAN 论文中的最后一个贡献是 StyleGAN2。它进一步建立在 StyleGAN 架构的基础上,并进行了一些关键的更改,以提高生成输出的质量。
权重调制与解调 Weight Modulation and Demodulation
StyleGAN2移除了AdalN层并应用权重调制和解调来提升图片质量。
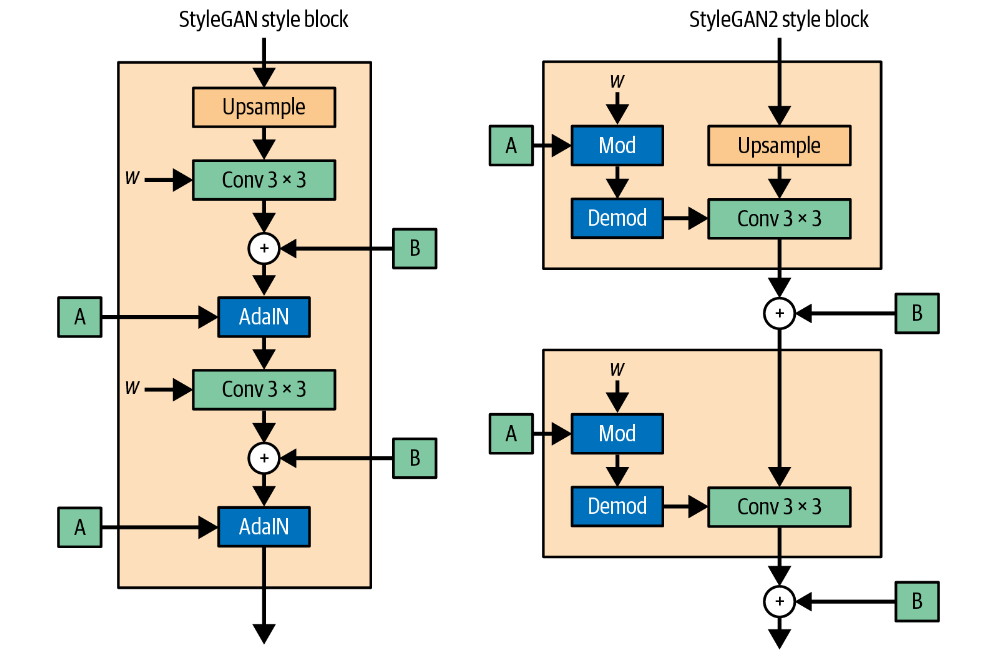
StyleGAN中的
AdaIN层只是一个归一化加风格调制(缩放和偏差)。
StyleGAN2的想法是在运行时将风格调制和归一化(解调)直接应用于卷积层的权重,而不是卷积层的输出。
在 StyleGAN2中,每个密集层\(\mathbf A\)输出单个风格向量 \(s_i\) ,其中 \(i\)
索引相应卷积层中输入通道的数量。然后将风格向量作用于权重:\(w_{i, j, k}^{\prime}=s_i \cdot w_{i, j,
k}\),即调制步骤。
接下来对调制的权重应用归一化,称为解调:\(w_{i, j, k}^{\prime \prime}=\frac{w_{i, j, k}^{\prime}}{\sqrt{\sum_{i, k} w_{i, j, k}^{\prime}+\varepsilon}}\)
路径长度正则化 Path Length Regularization
路径长度正则化在损失函数中引入了一个额外的惩罚项,我们希望潜在空间尽可能的平滑和均匀,以便任何方向上的潜在空间中固定大小的补偿都会导致图像中固定的变化。
为了实现这个目标,StyleGAN2旨在最小化以下函数:
\[ \mathbb{E}_{w, y}\left(\left\|\mathbf{J}_w^{\top} y\right\|_2-a\right)^2 \]
其中\(w\)是mapping network创建的风格向量集合,\(y\)是由\(\mathscr{N}(0,
\mathbf{I})\)绘制的受到噪音干扰的图像集合。\(J_w\)是生成器相对于风格向量的雅可比矩阵。
\(\left\|\mathbf{J}_w^{\top} y\right\|_2\)测量图像变化的大小,如上述,我们希望这个变化趋近于一个常数\(a\)
此外,为了提高效率,损失函数中的正则化项仅每 16 个小批量应用一次。这种技术称为惰性正则化 lazy regularization,不会导致性能明显下降。
非渐进式生长 No Progressive Growing
StyleGAN2 没有采用通常的渐进式训练机制,而是利用生成器中的跳跃连接和鉴别器中的剩余连接来将整个网络训练为一个整体。
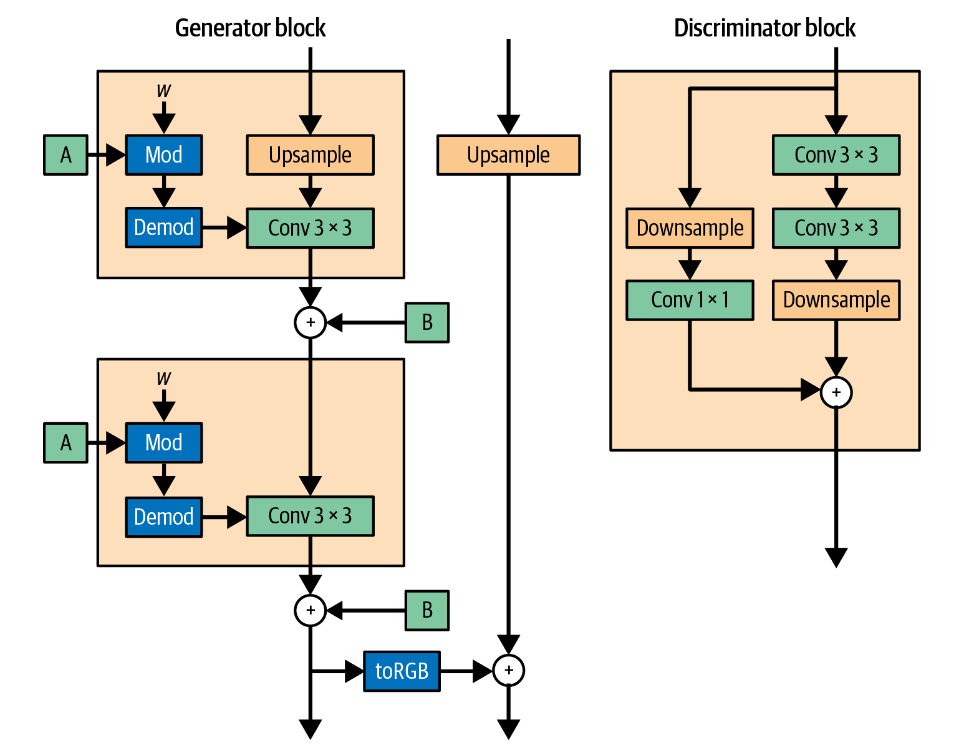
作者表明,使用这种架构确实保留了这个属性。每个网络都受益于在训练的早期阶段细化较低分辨率层中的卷积权重,而用于将输出传递到较高分辨率层的跳跃连接和残差连接几乎不受影响。随着训练的进行,更高分辨率的层开始占据主导地位。
https://github.com/autonomousvision/stylegan-xl
Self-Attention GAN (SAGAN)
SAGAN展示了Transformer机制引入GAN模型可能性。
https://github.com/brain-research/self-attention-gan
Self-Attention Generative Adversarial Networks
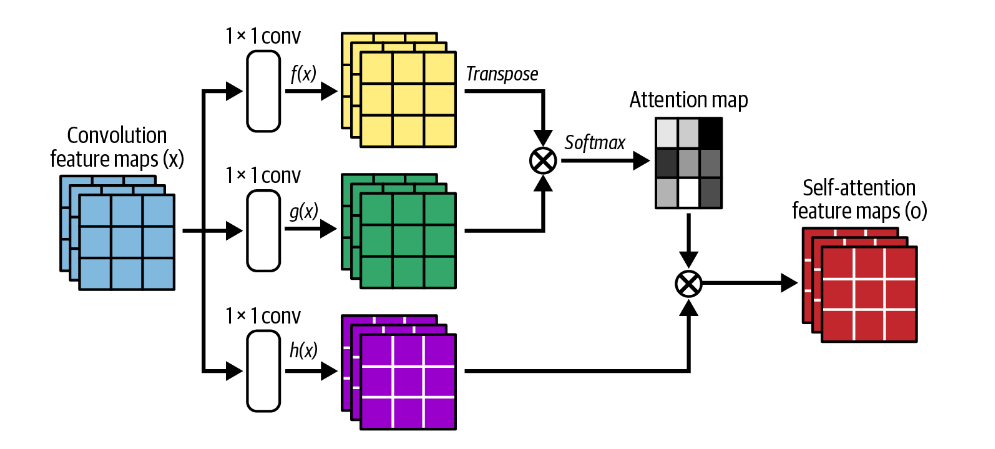
不包含注意力机制的基于 GAN 的模型的问题在于,卷积特征图只能在局部处理信息。将像素信息从图像的一侧连接到另一侧需要多个卷积层。在整个过程中,为了捕获更高级别的特征,精确的位置信息被减少,这使得模型学习远程连接像素之间的远程依赖关系的计算效率低下。

比如,红色点的相关信息都在鸟的身上,GAN比较容易处理。而绿色点的相关信息需要跨过鸟到另一侧。这并不容易被GAN学习到。而三色点所在的尾部本身细长,也是GAN不能很容易学习的特征。
BigGAN
BigGAN继承并扩展了SAGAN的思想。
Large Scale GAN Training for High Fidelity Natural Image Synthesis
使用 BigGAN 生成图像 | TensorFlow Hub
VQ-GAN
GAN 的另一种重要类型是矢量量化Vector Quantize GAN(VQ-GAN)。这项功罪最初由VQ-VAE引入。
通过离散潜在空间,即学习的向量列表(密码本),每个向量都与相应的索引相关联。VQ-VAE 中编码器的工作是将输入图像折叠为较小的向量网格,然后将其与码本进行比较。然后将与每个网格方向量最接近的码本向量(通过欧几里得距离)向前传送以由解码器进行解码。
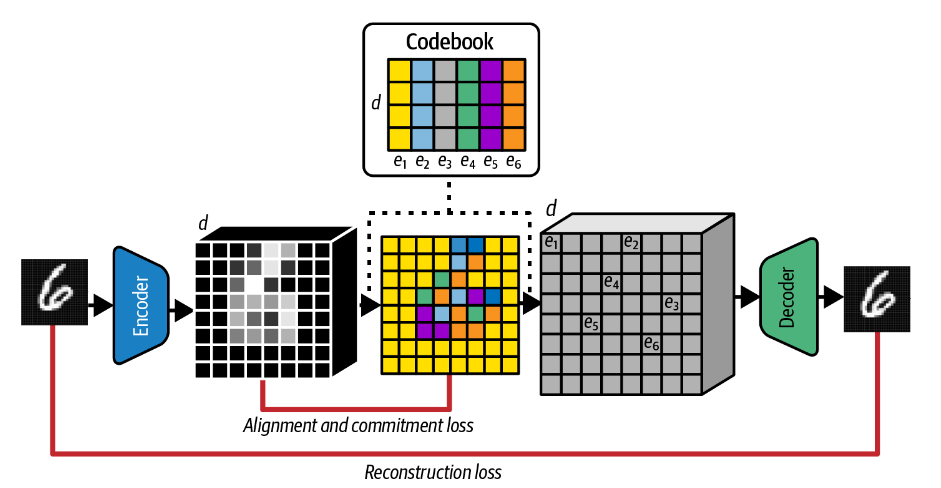
码本可以被认为是由编码器和解码器共享的一组学习的离散概念,以便描述给定图像的内容。
这种架构提出了一个问题:我们如何对新颖的代码网格进行采样以传递给解码器以生成新图像?显然,为每个网格方块以相同的概率选择编码是行不通的。作者使用了另一个模型,即自回归 PixelCNN,来预测网格中的下一个代码向量,给定之前的代码向量。
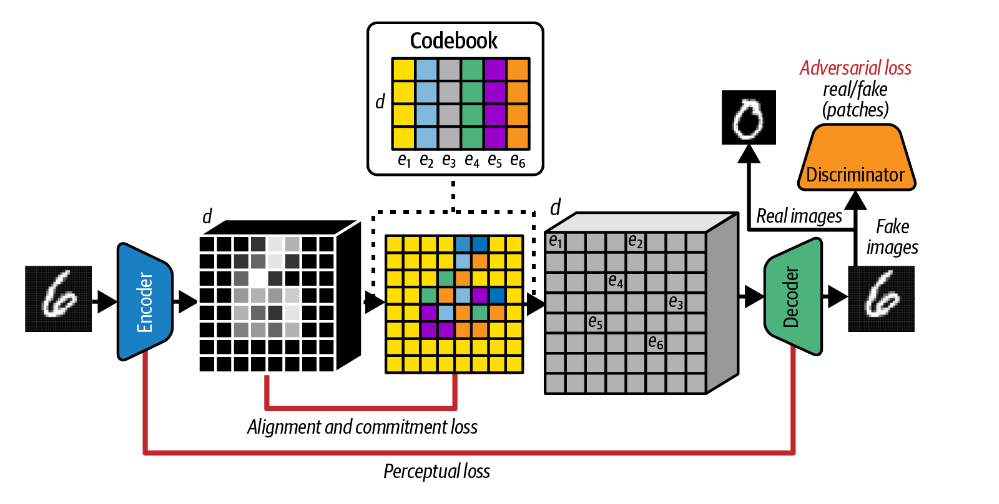
- 作者添加了一个 GAN 判别器,试图区分 VAE 解码器的输出和真实图像,并在损失函数中附带对抗项。这一添加提高了整体图像质量。
- 在此之后,GAN 判别器被修改为预测图像的一部分是真还是假,而不是一次性预测整个图像。由此,损失函数可以根据图像的风格而不是内容来衡量判别器区分图像的能力。
- 然后,VQ-GAN 没有使用比较输入图像像素与 VAE 解码器的输出像素的MSE损失函数,而是使用感知损失项Perceptual loss来计算编码器中间层特征图之间以及解码器的相应层的差异。
- 最后,使用 Transformer 代替 PixelCNN 作为模型的自回归部分,经过训练来生成编码序列。
ViT VQ-GAN
在2021年,Yu等人对 VQ-GAN 进行了最后的扩展,作者展示了如何用 Transformer 替换 VQ-GAN 的卷积编码器和解码器。
Vector-Quantized Image Modeling with Improved VQGAN
作者使用视觉变换器(ViT)将图像划分为一系列块patch,这些块patch被标记化,然后作为输入馈送到编码器 Transformer。
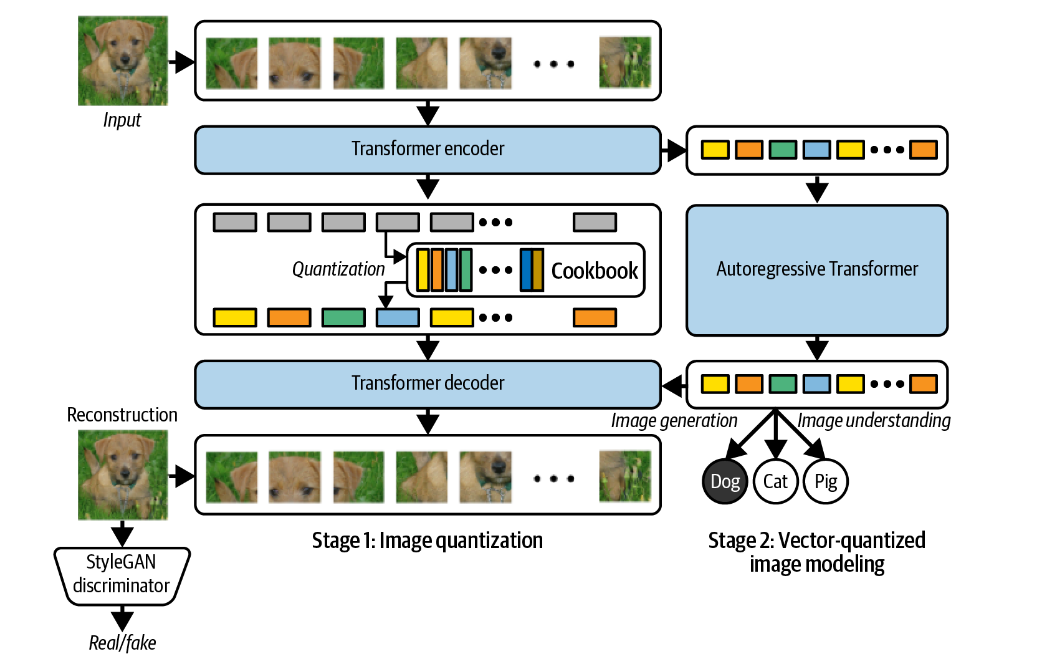
在ViT VQ-GAN中,图像块被首先展平,然后被映射到一个低维潜在空间,在这个过程中,位置编码也被引入。这些序列被馈送到标准编码器 Transformer,并根据学习的码本对生成的编码进行量化。
这些整数代码由解码器 Transformer 模型进行处理,整体输出是一系列可以拼接在一起以形成原始图像的补丁。
然后,与原始 VQ-GAN 模型一样,训练的第二阶段涉及使用自回归解码器 Transformer 生成代码序列。


